

You might have encountered software that is not easily testable, and by this I mean software that is not tested from the outset. You might have even tried to test it, but failed to do so. Don’t worry, software where testing is an after-thought is never going to be as testable as software designed to be testable from the beginning.
In this post, I’m going to explore how you can approach testing software where testing is an after-thought. I’ll cover the context you need to collect, a simple example of Golden Master Testing and one non-standard implementation of the Golden Master pattern.
Plus, I’ll share with you a practical example of how we approached this challenge with one of our clients - and the outcomes we were able to achieve.
Where do you start when working with code that was not built to be tested?
As a software consultancy, Codurance works with many clients and code that’s in different stages or states. In the scenario I'm going to share with you today, we were working with a client that had production code with little to no automated tests.
First and foremost, it was important we agreed a “safety net” should be in-place where a suite of automated tests could provide feedback on whether changes to production code have altered its behaviour.
Receiving this kind of feedback early-on is important, especially as relying on manual tests is going to result in slow feedback. This slow feedback might not reach a developer until hours, days, weeks after making a change.
Common characteristics of legacy code that make it difficult to test
Our client’s production code had a number of characteristics that you might expect of software written some years ago, and added to over time. All of this is important to understand to better appreciate how we made decisions.
Here are some of these characteristics, and other pertinent facts that helped shape our solution.
Heavily reliant on a database
The particular part of the code that we were testing relied heavily on the database (DB). By this I mean that it runs on a schedule and will query the DB to see if there is input to process. In this sense, the DB provides the input to the code we wanted to test. And of course, this means we needed to provide the input to the DB, but more on that later.
It is also important to highlight that the design of the system meant that the DB is actually integral to how the production code runs, controlling which branches of code are executed, for example. It won’t take much of a mental-leap to make the connection between that statement and the impact on how the software is tested. Yes, indeed you are thinking that a lot of data will need to be placed into the DB, prior to invoking the production code.
Next I want to tell you about the output - using the term loosely. I say this because the production code processes the input and writes data back to the DB, and here I will refer to this as “output”, even though it isn’t, but I don’t want to get caught in a philosophical debate about whether that is actually “input” to the DB. So, to summarise that last point, the observable behaviour of this part of the system is done by looking at the effect on the DB after the production code has completed.
Large code base which has grown over time
The code is large, and has been added to over time. The wording there is deliberate as the design hasn’t necessarily evolved, but new code has been added and sprinkled all over existing code. What you are left with is large and complex, with some very large classes and methods.
Here, the size of the code is important, as more code in this case meant more possible branches (code execution, nothing to do with Git). And because of the size, you could end up with making a change on line 2,000, and impact something that happens on line 10,000.
What this all means is that because the code was not designed to be testable when the code was authored, we couldn’t easily employ techniques that we would ordinarily use, as that would most likely involve making changes to the underlying large and complex code. In fact, doing so in the absence of such a “safety net” would make those changes potentially high-risk, which was extremely undesirable in this particular domain.
Old code (that hasn’t aged well)
Another important piece of context is the age of the code. We all know that it is uncommon for a piece of software to age as well as say wine or cheese, and when we refer to “legacy code”, we are not praising the legacy that has been left by people before us.
As mentioned before, the code had been added to over many years, and the code could well contain dead branches. This is extremely important as it underpins why we requested data from production as inputs, in addition to getting domain experts to categorise the behaviour, and source examples that tested this behaviour.
Context and environment are critical to enabling testing in legacy code
Perhaps you can already see that this wasn’t a situation for standard Golden Master testing. We had to iteratively work our way towards a solution, based on surveying the environment and soaking up all of the context and facts. But let’s first provide a refresher on Golden Master testing.
What to do when you can’t use standard Golden Master testing
Before jumping into the approach and our solution, I thought it would be worth a small refresher on Golden Master Testing by working through a simple example.
Golden Master Testing - a quick refresher
For those of you more familiar with the Golden Master technique, you will typically see things such as the below in literature:
Record the outputs, for a set of given inputs
This is very simple, and if you have written them yourself, you probably had a text file with the inputs, and a text file with all of the outputs.

Where your input might look like:
1 Name: Sam, Age: 1052 Name: Bob, Age: 343 Name: Linda, Age: 26
And the output:
1 Can retire: true
2 Can retire: false
3 Can retire: false
It’s simple, and each line correlates to a single scenario. For example, when the production code gets Sam and he is 105, we can see that the production code says he can retire.
We all love simple code, and the simplicity of the above, but we did not have the luxury of writing such a simple implementation. However, we wanted to assess if a Golden Master approach would actually work, and more importantly, be worth the investment.
In the context of our client, this approach was just too simple to work. Instead, we had to take a bespoke approach which started out with manual testing.
Start by experimenting with a manual test
We started writing a single test written by-hand. You can compare this to a single line of the aforementioned text file, which usually correlates to a single scenario. However, unlike the simple example described earlier, ours was not a single line. For this single scenario, we required setup in a number of tables in the database, that had to be inserted in a specific order, requiring careful orchestration, given the database constraints.
This was the equivalent of us dipping our toes in the water, and was necessary to get feedback on our approach. During this experiment, we concluded (amongst other things) that these tests were slow to write, and so we decided to explore if there was a better way.
Hypothesise, identify opportunities and experiment
You might have heard advice along the lines of “you shouldn’t automate straight away”, and this is sensible advice. We were following this when we started writing the tests manually. As previously mentioned, there were a number of tables that we had to setup, prior to invoking the production code. Now, we identified that large parts of this setup could be determined from the input to the production code.
So we asked ourselves:
Can we generate tests, using the input for the required setup?
If we were able to do this, it would save the laborious work of creating the setup from the information in the input, time-and-time again, for each scenario. At that point in time, imagine reading a piece of paper and then entering parts of that information digitally via a computer. That is how it felt.
We experimented and found this approach of automatically creating the setup from the input to be promising. So we backed this approach and continued on this journey.
A Smarter, Automated Solution
We chose to record what the production code did by seeing what effect it had on the DB. In our context, the DB is core so this was perfectly reasonable.
What this meant was that we would run the production code with each input, and capture what happened to the DB (i.e. The side-effects).
Practical example of testing legacy code reliant on a database
Here I’ll take you through what we did to test legacy code by capturing changes to the database.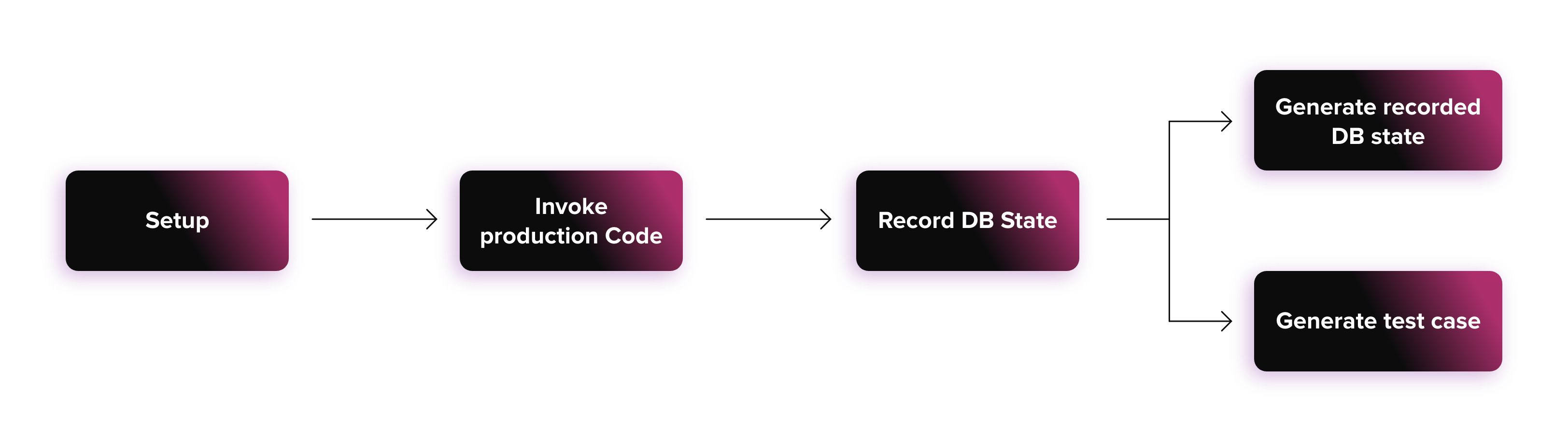
The above shows a very simplified view of how the behaviour of the production code is captured, and how tests are generated.
Let’s dive a bit deeper into each of these steps, to describe in more detail what they are doing.
Setup
Goal - setup the “world” so that the production code will run as expected
Examples - inserting data into DB, provisioning a mock FTP server
Invoke Production Code
Goal - trigger part of the production code, in a way that is representative of how it is actually used in production
Examples - calling runSomething() method on class named TheLegacyCode
Record DB State
Goal - identify which tables were written to, and capture the contents of those tables
This step is quite specific, and could take many forms. I have provided a concrete example for simplicity.
Generate recorded DB state
Goal - store the state of the DB after invoking the production code. This forms the basis of assertions that are used to check if the state of the DB has changed when the test cases are run.
Generate test case
Goal - generate a file that represents a test, and has all of the information needed to locate the input and expected output (to use this term loosely) for a particular scenario.
Database-centric, large and complex legacy code can be tested
Before we added this test suite, many probably uttered “this code cannot be tested”, but we provided a way to prove that it can be tested, and provide people with options if they find themselves in a similar situation.
We found the approach we took had several advantages including:
Faster feedback
As stated in literature many times, getting feedback faster is always desirable, and this test suite did provide this.
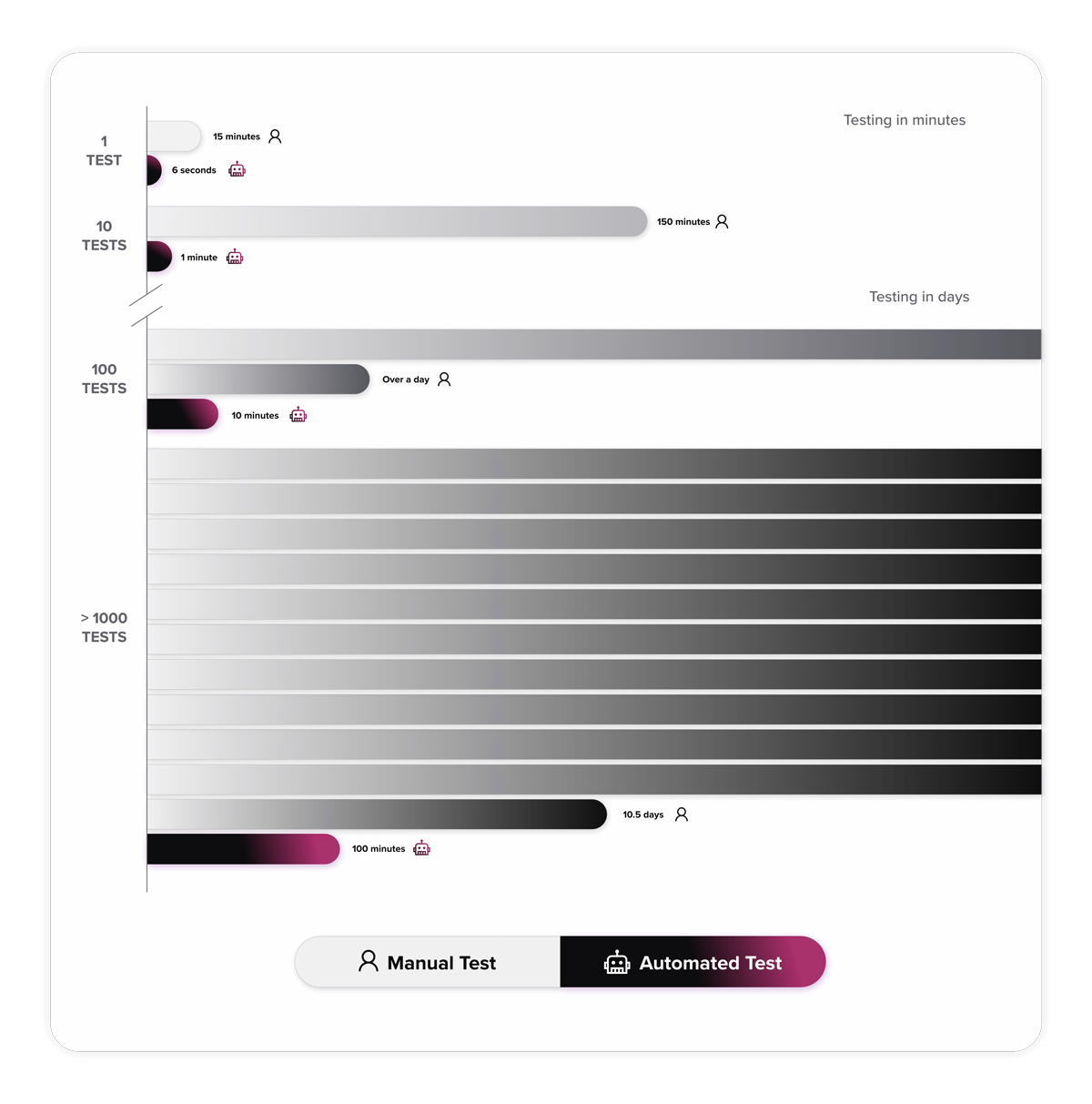
The time-saving is actually quite astounding. It takes 2.5 hours for one manual tester to run 10 manual tests, whereas it only takes one minute to run 10 automated versions of those manual tests. You appreciate this even more when you understand that the Test Suite is around 1000 tests, and to run 1000 manual tests would take 10.5 days (for a person working 24 hours a day), whereas the automated tests will complete within 1hr 40m.
The time saving is quite something, but the automated testing also allows for more flexibility for developers to run tests on-demand whenever they want. Unfortunately, you can’t do the same with a Manual Tester, tap the keyboard three times and they appear.
 Increased flexibility
Increased flexibility
Our specific approach of generating these tests meant that we could pivot much faster than manually creating them. For instance, if we needed to assert on a previously-unknown-table, we could configure it in the tool, and then regenerate all of the tests, where now the new table is captured in the “recorded DB state”. This was very useful, especially as we did not have all of the knowledge up-front, and we could expand our tests as our knowledge increased.
Opportunity to introduce automation
This might seem like I am stating the obvious, but this was one of the first instances this code actually had some form of automated tests. In particular, these tests actually cut straight to the heart of this part of the system, and tested the core logic, which is something that had not happened before.
Test legacy code with more confidence
We found a way to iteratively work towards establishing a suite of Golden Master tests as a means to change the underlying code with more confidence and chip-away at the fear-complex that can form. The client actually commented on how they no longer have the fear they once had, and that fear has dissipated.
One important thing to highlight is that after you establish a Golden Master suite, you can then start to modernise the legacy codebase in confidence.
As you start modernising the codebase and adding tests further down the pyramid (e.g. unit tests), you will achieve faster feedback and become less reliant on just the Golden Master tests.
As always, context is important and I hope you understand that all techniques have a time and a place, and even how those techniques are applied will depend considerably on the context.
Knowledge sharing is important, and we would love to hear your experiences with testing legacy code.