
Quando comecei minha jornada como um Software Craftsperson profissional, um dos muitos livros que li foi “Growing Object Oriented Software Guided By Tests” de Steve Freeman e Nat Pryce. Uma das coisas que realmente me impressionou foi a noção de que software é algo que deve ser cultivado e nutrido ao longo do tempo. Assim como cuidamos regularmente de nossas plantas e flores para garantir que cresçam da melhor maneira possível, devemos nutrir continuamente nosso software.
Neste artigo, gostaria de explorar por que isso é importante, delinear alguns sinais reveladores de que seu software está em declínio e algumas das coisas que você pode fazer para lidar com isso.
O que é Software Rot?
Para começar, vamos definir o que queremos dizer com Rot de software. Pode parecer estranho se referir ao software como tendo a capacidade de "apodrecer". Claro, intelectualmente sabemos que isso não acontece. Em vez disso, o que é chamado de de software rot é uma base de código se tornando difícil de manejar devido à complexidade de código não gerenciado e design inadequado, entre outros motivos.
Também é importante considerar o ambiente e o contexto mais amplos nos quais nosso software está sendo executado. O cenário tecnológico está em constante mudança. Um exemplo particularmente bom disso é a proliferação de frameworks JavaScript nos últimos anos. À medida que novas tecnologias surgem e desaparecem, as comunidades construídas em torno delas e o suporte e a evolução delas também diminuem.
Se não tomarmos cuidado, podemos acabar executando um framework ou biblioteca específica que não é mais amplamente suportada e trabalhada ativamente. Isso nos deixa em perigo de quaisquer bugs naquele framework ou riscos de segurança que não serão corrigidos. Isso também significa que provavelmente ficaremos para trás à medida que novas bibliotecas e frameworks forem introduzidos, adotando novos padrões, tecnologias e até mesmo recursos de linguagem. Se nosso software estiver simplesmente parado neste ambiente em constante mudança, isso pode levar à podridão.
Indicadores de Podridão de Software (Software Rot)
Agora que temos um entendimento comum sobre podridão de software, gostaria de delinear alguns dos sinais que podem ser indicativos de que a podridão de software está começando a se instalar. É importante observar que esta seção se refere apenas a indicadores. Ou seja, esses sinais dirão que você tem um problema, mas não necessariamente dirão a causa subjacente do problema.
1. Fragilidade
Fragilidade se refere ao software que tende a quebrar em muitos lugares sempre que uma mudança é feita, muitas vezes até mesmo em áreas que são conceitualmente não relacionadas à mudança que está sendo feita. À medida que isso aumenta, o software se torna muito difícil de manter porque cada nova mudança introduz vários novos defeitos. No melhor dos casos, esses defeitos são detectados cedo por um conjunto de testes automatizados.
No pior dos casos, eles são encontrados na produção pelos usuários finais. Essa fragilidade pode então levar a uma perda de credibilidade para o software e para a equipe que o possui.
2. O tempo para entregar recursos aumenta
Um indicador particularmente forte de podridão de software é quando uma equipe começa a ver o tempo necessário para entregar valor aumentando. Uma quantidade cada vez maior de tempo necessária para adicionar novos recursos é um sinal de rigidez de código. Isso efetivamente significa código que é difícil de mudar, na maioria das vezes porque o código é fortemente acoplado.
Por exemplo, uma nova mudança causa uma cascata de mudanças subsequentes em módulos dependentes dentro da base de código. Isso resulta em equipes frequentemente temerosas de abordar problemas não críticos porque não sabem o impacto total de fazer uma mudança, ou quanto tempo essa mudança levará.
3. Lutando para acompanhar as demandas do negócio
Intimamente ligado ao ponto anterior, quando uma equipe começa a lutar para acompanhar as demandas da organização, isso também é uma indicação de que a base de código pode estar em um estado não saudável.
Por exemplo, talvez o modelo de domínio na base de código não seja mais adequado e exija um novo design para facilitar as necessidades dos requisitos do negócio. Quando uma equipe de software não consegue acompanhar as demandas da organização, há um problema sério. Isso significa que a organização corre o risco de perder qualquer vantagem competitiva que tenha no mercado, pois demora mais para enviar novos recursos aos seus clientes.
4. Change Failure Rate
É muito bom implantar seu software em produção com frequência, mas se essas implantações resultarem em mudanças drásticas introduzidas que impactam a capacidade do seu cliente de usar seu produto, isso não é nada bom. Queremos implantar em produção regularmente, mas não ao custo da qualidade.
Change Failure Rate é uma métrica que foi introduzida pela equipe de DevOps Research and Assessment (DORA) e é uma medida de quantas vezes uma implantação em produção resulta em uma falha de algum tipo sendo introduzida. Uma taxa de falha de mudança alta ou crescente sugere que nosso software não está tão saudável quanto deveria e provavelmente está faltando portões de qualidade adequados no caminho para a produção. Escrevi sobre Change Failure Rate com mais detalhes como parte de um artigo anterior, que você pode encontrar aqui.
5. Métricas de Software em Declínio
Métricas de software são essencialmente medidas de certos atributos de qualidade de uma base de código. É importante notar que eu desaconselho procurar números absolutos em qualquer um desses atributos. Em vez disso, é muito mais útil focar na tendência ao longo do tempo. Um declínio nos diz que nosso software se tornou menos saudável em uma determinada área e devemos tomar medidas para resolver isso, para evitar que o software se deteriore.
Há uma série de métricas que podem ser coletadas sobre uma base de código de software, a lista a seguir não é exaustiva, mas uma coleção daquelas que pessoalmente achei úteis nas equipes com as quais trabalhei: Complexidade Ciclomática, Acoplamento e Cobertura de Teste.
-
Complexidade Ciclomática
Muitas vezes ouço equipes usando o número de linhas de código (LOC) em um determinado método/arquivo como uma medida de complexidade. Isso por si só não é uma métrica boa o suficiente. Por exemplo, um pequeno programa de software totalizando 50 linhas de código não parece excessivamente complexo. Mas se essas 50 linhas de código contivessem 25 linhas de construções de código "se-então" consecutivas, então o código é realmente extremamente complexo!
É aqui que a Complexidade Ciclomática é uma métrica muito melhor. É uma medida do número de caminhos ou ramificações diferentes. Com base na teoria dos grafos e desenvolvida por Thomas J. McCabe, ela fornece uma medida quantitativa do número de caminhos linearmente independentes através do código-fonte.
-
Acoplamento
Existem duas categorias de acoplamento de componentes de software. Primeiramente, Acoplamento Aferente. Isso se refere ao número de classes em outros pacotes que dependem de classes dentro de um pacote específico. É um indicador da responsabilidade do pacote. A outra categoria é Acoplamento Eferente. Esse é o número de classes em outros pacotes das quais as classes no pacote dependem.
Esse é um indicador da dependência do pacote em externalidades.outgoing. Quanto maiores os níveis de acoplamento em ambas as categorias, mais difícil será alterar o código do software.
Queremos nos esforçar para componentes fracamente acoplados, pois isso aumenta a flexibilidade, a usabilidade e reduz a área de superfície para alterações. Em contraste, bases de código com componentes fortemente acoplados tendem a ser mais frágeis e muito mais difíceis de alterar e evoluir ao longo do tempo.
6. Cobertura de Teste
A Cobertura de Teste é uma medida da quantidade de código de produção em uma base de código de software que tem um teste automatizado para exercitar e afirmar contra seu comportamento. Essa métrica é geralmente expressa como uma porcentagem, ou seja, uma equipe pode dizer "temos 70% de cobertura de teste". Como descrevi anteriormente no artigo, eu sempre aconselharia não procurar um número absoluto com métricas de software e isso é especialmente verdadeiro para cobertura de teste.
Em vez disso, prefira observar tendências ao longo do tempo e medidas relativas de cobertura de teste entre diferentes partes de uma base de código, particularmente aquelas que mudaram recentemente. Por exemplo, se sua equipe fez um grande número de alterações recentemente em uma área da base de código para dar suporte a um novo recurso, seria alarmante se a cobertura de teste nessa área tivesse diminuído.
7. Dívida Técnica Crescente
Dívida Técnica é uma metáfora que foi criada por Ward Cunningham, em 1992. Ele escreveu:
“Enviar código pela primeira vez é como entrar em dívida. Uma pequena dívida acelera o desenvolvimento, desde que seja paga prontamente com uma reescrita... O perigo ocorre quando a dívida não é paga. Cada minuto gasto em código não muito certo conta como juros sobre essa dívida. Organizações de engenharia inteiras podem ser paralisadas sob a carga de dívida de uma implementação não consolidada, orientada a objetos ou não."
Em outras palavras, dívida técnica é quando priorizamos entrega rápida em vez de qualidade de código. No curto prazo, isso é aceitável. No entanto, se a dívida técnica não for paga a tempo, pode levar à deterioração do software.
8. Experiência do desenvolvedor
A experiência do desenvolvedor (DevEx) também pode ser um bom indicador de podridão de software. Os desenvolvedores passam a maior parte do tempo trabalhando em uma base de código. Se essa base de código for difícil de trabalhar, isso afetará seu moral, o que pode levar ao declínio do moral geral da equipe também. Prestar atenção à felicidade do desenvolvedor pode realmente dizer muito sobre o estado da(s) base(s) de código em que eles trabalham. Uma base de código com a qual os desenvolvedores gostam de trabalhar é geralmente um sinal de uma base de código saudável. Afinal, nenhum desenvolvedor realmente gosta de trabalhar com uma base de código complexa, altamente acoplada e frágil.
Conforme mencionado anteriormente, se você tiver algum desses problemas em suas equipes, recomendo fortemente que dê uma olhada mais de perto na base de código do software de sua equipe. Saber que esses problemas são bons indicadores de que nosso software não está em uma posição saudável é um bom ponto de partida. Mas isso ainda não nos ajuda a entender a(s) verdadeira(s) causa(s) subjacente(s). Esses indicadores mencionados também podem ser pensados em duas dimensões: indicadores líderes e indicadores atrasados. Precisamos, em última análise, nos aprofundar no software para resolver o(s) problema(s).
Lidando com a podridão do software
Usei a analogia de plantas e flores anteriormente neste artigo para ilustrar que o software deve crescer continuamente ao longo do tempo. Efetivamente, queremos que nossas bases de código de software suportem evolução e mudança incremental. Conduzir para esse objetivo nos encorajará a considerar coisas como complexidade de software, testabilidade, o acoplamento apropriado entre componentes e assim por diante.
Uma das principais coisas que as equipes precisam adotar é a refatoração contínua de suas bases de código. Seja removendo código "morto" não utilizado, removendo duplicação de código ou simplificando modelos de design, tudo isso ajuda a manter uma base de código limpa, minimizar a complexidade e, finalmente, manter o custo de fazer alterações baixo.
1. Valor Testabilidade
Testabilidade em sua forma mais básica é uma medida de quão fácil é testar um software específico. Também pode ser expressa como o grau de probabilidade de um teste destacar um defeito no software. Também ouvi pessoas se referirem à testabilidade como a probabilidade de um teste ser escrito! A teoria, é claro, é que se o software for difícil de testar, há uma chance maior de que isso não aconteça. O teste é de vital importância, principalmente o teste automatizado.
Outra coisa que aprendi lendo Growing Object Oriented Software Guided By Tests foi que o teste automatizado não era apenas sobre garantir que o software se comportasse como esperávamos. Era também sobre projetar nosso software. É por isso que o Test Driven Development (TDD) é uma parte tão vital do desenvolvimento de software. Ao valorizar a testabilidade e tratá-la como um cidadão de primeira classe, permitimos que nosso design de software surja gradualmente de forma incremental. Cada incremento se baseia no anterior e cria um conjunto de testes automatizados.
Este conjunto de testes então atua como uma rede de segurança para quando precisamos fazer alterações. Muitas vezes, a testabilidade é considerada uma reflexão tardia. Mas eu o encorajaria muito a tratá-la como uma preocupação de primeira classe.
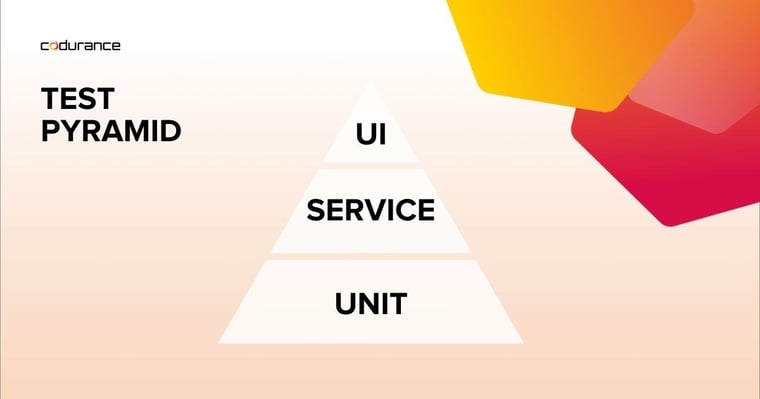
Também é importante observar que um conjunto de testes automatizados deve compreender diferentes tipos de testes que exercitam várias partes da base de código. Em seu livro Succeeding With Agile, Mike Cohn criou o conceito de “Pirâmide de Testes”. É um bom guia visual para ajudar as equipes a pensar sobre diferentes camadas de testes. Também ajuda a orientar muitos testes a serem feitos em cada uma das camadas, em relação umas às outras.
Este é frequentemente um bom ponto de partida para as equipes discutirem como deve ser seu conjunto de testes de automação. Idealmente, um bom conjunto de testes automatizados deve compreender principalmente pequenos testes unitários que sejam rápidos de executar e nos forneçam feedback de que um componente individual isoladamente se comporta conforme o esperado. Mas esses testes por si só não são suficientes, então precisamos de outros tipos de testes que garantam que vários componentes funcionem juntos conforme o esperado. Eles tendem a ser um pouco mais lentos, pois seu escopo é mais amplo, embora sejam importantes, geralmente há menos deles em comparação aos testes unitários. Isso garante que o conjunto de testes automatizados forneça um loop de feedback oportuno.
A imagem acima mostra um exemplo muito básico de Pirâmide de Testes, com os diferentes tipos de teste em cada nível. Pode ser um exercício útil para equipes analisarem seu conjunto de testes de automação e verem se eles têm uma quebra de teste em forma de pirâmide ou não. Por exemplo, eu vi equipes que tiveram uma forma de pirâmide inversa (ou seja, muito mais testes de ponta a ponta de IU do que testes de nível de serviço ou unidade). Isso significava que seu conjunto de testes era lento para executar e quando esses testes orientados por IU quebravam, muitas vezes era difícil raciocinar o porquê. Além disso, essa equipe sofreu com uma série de bugs de "caso extremo" de produção como resultado da falta de testes de unidade individuais em torno de cada componente.
2. Esforce-se pela Simplicidade
Um princípio fundamental a ter em mente no design de software é a simplicidade. A comunidade Extreme Programming (XP) fala sobre Design Simples e frases como "Faça a Coisa Mais Simples que Possivelmente Funcionaria" e "Você Não Vai Precisar Disso" (comumente chamado de YAGNI).
Ao nos esforçarmos pela simplicidade, alcançamos duas coisas - permitimos que nosso software evolua incrementalmente ao longo de uma série de pequenos passos, cada um construindo um sobre o outro e contendo apenas design suficiente para atender aos requisitos naquele momento.
Em segundo lugar, reduzimos a complexidade. Quanto mais complexo for um design, mais difícil será raciocinar sobre ele. Também é possível que projetemos com o futuro em mente e nossas previsões estejam incorretas. Como resultado, o complexo que construímos não é realmente adequado para o propósito e requer retrabalho, onde teríamos sido muito melhores mantendo-o simples, para começar.
3. Suporte à Mudança Incremental
A mudança incremental é a ideia de que as mudanças que precisam ser realizadas em uma base de código de software são divididas em pedaços menores e aplicadas por vez. Fazer isso significa que reduzimos o escopo de cada mudança e, portanto, a complexidade e o risco associados a ela. Queremos que nossas bases de código de software sejam capazes de suportar essa abordagem de mudança incremental.
4. Estabelecer Diretrizes Comuns de Codificação
É importante para uma equipe de desenvolvimento de software ter um entendimento compartilhado do que "saudável" significa para seu software. Isso é verdade por dois motivos. Primeiro, garante que todos os membros da equipe estejam puxando na mesma direção, mas também cria um contrato social dentro da equipe, para manter a qualidade do software e do código alta. Uma boa maneira de fazer isso é por meio de um conjunto de diretrizes e princípios comuns que a equipe cria em conjunto. Se a equipe escolher, eles podem ser codificados na forma de regras de linting automatizadas, limites para métricas de base de código e outros.
Quando isso é bem feito, uma base de código deve parecer e ser escrita pela mesma pessoa. Com muita frequência, os membros da equipe têm opiniões diferentes sobre design e estilos de código e essas opiniões diferentes são expressas no código. Por exemplo, uma infinidade de padrões para atingir coisas semelhantes, nomenclatura inconsistente ou falta de estrutura de base de código clara. Todas essas coisas introduzem complexidade acidental a uma base de código e podem dificultar a mudança ao longo do tempo.
5. Refatorar, Pequeno e Frequentemente
No livro Extreme Programming Explained, Kent Beck se refere ao desenvolvimento de software Agile como sendo semelhante a dirigir um carro.
“Usamos dirigir como uma metáfora para desenvolver software. Dirigir não é apontar o carro em uma direção e segurá-la; dirigir é fazer muitas pequenas correções de curso.”
Embora a metáfora tenha sido usada no livro para falar principalmente sobre o ato de planejar dentro de projetos de desenvolvimento de software Agile, acho que a metáfora também é verdadeira para o design de software. Vejo o ato de refatoração como as correções de curso às quais Kent Beck se refere e, ao fazer essa refatoração com frequência, podemos manter cada uma pequena para que façamos muitas pequenas correções de curso. Cada uma dessas refatorações, embora não altere a funcionalidade do software, desempenha um papel vital. Ela refina o software um pouco a cada vez para corresponder a algum novo entendimento que temos sobre o mundo e manter o código gerenciável.
Se nos encontrarmos em uma posição em que temos que lidar com refatorações em larga escala, geralmente é um sinal de que não temos feito a refatoração pequena e frequente. Como resultado, nosso design de software saiu de sincronia com o modelo de domínio do mundo real e agora surgiu um novo requisito que não se encaixa mais no modelo que temos em nosso software. Alternativamente, refatorações em larga escala podem ser um sinal de alta complexidade em uma área da base de código que se desenvolveu ao longo do tempo e atingiu um ponto em que a equipe não pode mais adicionar alterações efetivamente nessa área do código.
6. Radiadores de Informação
No contexto do desenvolvimento de software, os Radiadores de Informação são exibições visuais que apresentam algum insight sobre o estado atual do software. Eles geralmente são exibidos em grandes monitores dentro do espaço da equipe e apresentam informações como o estado atual da construção do software, visão geral do conjunto de testes automatizados, métricas de software e assim por diante. Eles são exibidos em um local altamente visível para que não sejam visíveis apenas para a equipe de software, mas também para as partes interessadas mais amplas dentro da organização que entram no espaço da equipe.
Ao usar os Radiadores de Informação, as equipes estão mostrando abertamente a saúde de seu software e, ao fazer isso, ajudam a ampliar quaisquer problemas potenciais com a saúde do software que possam surgir. Se o conjunto de testes automatizados, por exemplo, começar a ter uma falha, isso deve ser altamente visível em um monitor, tanto que seja difícil ignorar e solicite ação imediata, que é um dos principais aspectos disso. Ao adotar os Radiadores de Informação, ele promove uma cultura de transparência - a equipe está dizendo que não tem nada a esconder dos visitantes e das partes interessadas. Mas talvez o mais importante seja que isso também transmite à equipe que ela não tem nada a esconder de si mesma e que reconhecerá quaisquer problemas que surgirem de frente, em vez de escondê-los.
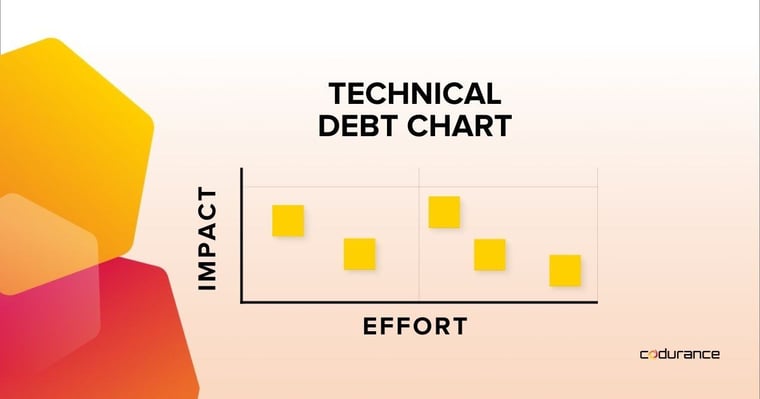
Um bom exemplo de um Radiador de Informações que vi muitas equipes adotarem é um "Gráfico de Dívida Técnica". Ele geralmente é colocado em uma parede dentro do espaço da equipe e é um gráfico onde os membros da equipe colocam cartões detalhando itens de dívida técnica. Os cartões são colocados em itens apropriados com base em dois eixos: esforço e impacto. Isso ajuda a dar uma indicação rápida do tipo de dívida técnica que a equipe tem e o valor absoluto, mas também a torna muito visível.
Os membros da equipe se reúnem regularmente e se reúnem em torno do gráfico para discutir os itens. Isso é importante por dois motivos - primeiro, para verificar se os cartões ainda estão colocados na posição correta de acordo com o esforço e o impacto. É importante observar que, à medida que a base de código evolui, alguns itens de dívida técnica podem exigir mais esforço para serem resolvidos. Além disso, a equipe pode estar ciente da necessidade de alterar uma área específica da base de código onde há alguma dívida técnica pendente. Nesse caso, pagar essa dívida técnica agora provavelmente terá um grande impacto, pois pode acelerar o desenvolvimento dessas novas mudanças.
Considerações finais
Este artigo tentou aumentar a conscientização sobre a podridão de software reunindo uma definição do que isso significa, alguns indicadores para ficar atento e, finalmente, algumas coisas para se armar para lidar com a podridão de software. Se você está lendo este artigo prestes a embarcar na construção de um novo software, pode pensar que a podridão de software não é algo que você precisa considerar. Eu alertaria contra isso.
Ao adotar a teoria da Arquitetura Evolucionária desde o início, sua equipe pode estar na vanguarda para se proteger e minimizar a podridão de software. A combinação de acoplamento apropriado e suporte a mudanças incrementais garantirá que a complexidade da sua base de código seja baixa. Colocar em prática mecanismos de detecção automatizados, como métricas de base de código e testes automatizados, permitirá que você identifique rapidamente quando sua base de código estiver começando a se desviar do curso e permitirá que você tome as medidas adequadas antecipadamente para minimizar o impacto de qualquer podridão de software.
Também é importante entender que é vital nutrir e desenvolver continuamente nossas bases de código de software. Em um mundo em constante mudança, o software que fica parado naturalmente "apodrecerá" à medida que o cenário tecnológico e as expectativas do cliente mudam rapidamente. Embora tenham sido criadas em 1974, as leis de evolução de software de Lehman, particularmente as duas primeiras, ainda são muito relevantes hoje: "um sistema deve ser continuamente adaptado ou se tornará progressivamente menos satisfatório", "conforme um sistema evolui, sua complexidade aumenta, a menos que seja feito trabalho para mantê-lo ou reduzi-lo".
Para recapitular, aqui está uma análise dos indicadores de software rot a serem observados e algumas das maneiras de lidar com eles:
Indicadores de Software Rot:
- Fragilidade
- O tempo para entregar recursos aumenta
- Lutando para acompanhar as demandas da organização
- Alta taxa de falha de mudança
- Métricas de software em declínio
- Dívida técnica crescente
- Moral do desenvolvedor
Maneiras de lidar com Software Rot:
- Testabilidade de valor
- Esforce-se pela simplicidade
- Suporte à mudança incremental
- Refatoração, pequena e frequente
- Estabeleça diretrizes comuns de codificação
- Radiadores de informações