
Bem-vindos a um novo capítulo da série “Technical pills about Platform Engineering: beyond what you find in the documentation”, onde a nossa equipa de plataformas partilha o seu conhecimento com base em experiências do nosso dia-a-dia. No post anterior falámos acerca da Configuração do DMS para DocumentDB: onde estão meus indexes?
Hoje vamos partilhar como transformámos uma grande quantidade de logs durante a análise de um incidente de segurança. Junta-te a nós nesta viagem onde partilhamos como processar objetos S3 de forma simples e flexível, numa arquitetura de serviços geridos
Os Logs são recursos essenciais para uma melhor observação dos bastidores dos sistemas, igualmente importante é a capacidade de se extrair informação útil de grandes quantidades de dados com o objectivo de apoiar melhor as nossas decisões (data-driven decisions). Neste artigo vamos detalhar a nossa forma de abordar e ajudar os nossos clientes na análise de actividades suspeitas de rede, permitindo-lhes responder de forma eficaz na recolha de dados e resposta a incidentes de segurança.
O GuardDuty é um serviço da AWS, que detecta ameaças de segurança, através de algoritmos com recurso a Machine Learning e mecanismos de proteção pró-activos contra potenciais ameaças. Apesar, desta enorme capacidade, cada descoberta deve ser cuidadosamente analisada para despistar eventuais falsos positivos. Um exemplo prático acontece por ex. quando é detectada atividade suspeita numa instância EC2. Nestas situações, é crucial investigar potenciais movimentos laterais por parte do atacante para obter acesso indevido a outros recursos do VPC. Como podemos validar essa atividade através dos VPC Flow Logs ?
Optámos por uma abordagem simples, e com algumas linhas de Python, numa função Lambda, conseguiriamos obter os ficheiros e envia-los para a nossa plataforma de visualização de dados - Data Visualisation Platform (DVP).

Em menos de uma hora implementámos esta integração, mas descobrimos rapidamente que a leitura dos dashboards seria difícil de interpretar, como demonstra este exemplo.
Exemplo de alguns registos num VPC Flow Log:
5 52.95.128.179 10.0.0.71 80 34210 6 1616729292 1616729349 IPv4 14 15044 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 19 52.95.128.179 10.0.0.71 S3 - - ingress OK5 10.0.0.71 52.95.128.179 34210 80 6 1616729292 1616729349 IPv4 7 471 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 3 10.0.0.71 52.95.128.179 - S3 8 egress OK
Teríamos de alterar estes IDs e substitui-los por informação útil e mais fácil de interpretar-mos:
|
Campo |
Descrição proposta |
|
|
Interface description |
|
|
Subnet name |
|
|
VPC name |
|
|
Subnet Name |
|
|
Subnet Name |
Este artigo não descreve o processo de mapeamento dos dados por uma questão de simplificação. Apenas consideremos que existe um processo externo que gere esse mapeamento e os dados finais ficam acessíveis na nossa Lambda.
Após o mapeamento, iniciámos os nossos testes para um único ficheiro, parecia perfeito. No entanto, quando o mesmo teste foi repetido mas os logs respeitantes a ma hora completa, o resultado foi catastrófico, rapidamente atingirmos os 15 minutos de tempo limite máximo (Lambda), e nem sequer conseguimos processar metade dos logs.
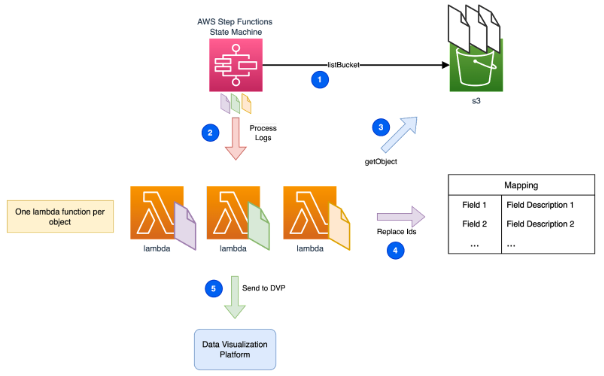
A solução passaria por dividir o problema em pequenas partes, processando os ficheiros individualmente. Mas como poderíamos fazê-lo de forma eficiente para centenas ou mesmo milhares deles? A resposta é AWS Step Functions!
Como é que funciona?
O AWS Step Functions tem um recurso chamado Map State, que itera de forma eficiente uma coleção de objectos S3. Cada objecto é mapeado para uma execução independente de lambda.
Step Functions
- A execução é iniciada de forma manual, o utilizador deve configurar o prefixo como parâmetro de entrada para que todos os objectos que partilham esse prefixo sejam processados.
- Por cada objeto identificado, a Step Function invocam uma função Lambda, que recebe como parâmetro de entrada o objeto em análise.
Lambda
3. A função lambda começa por descarregar o ficheiro em análise do Bucket S3 e lê o seu conteúdo, podendo ser necessário desencripta-lo e/ou descomprimi-lo para que o seu conteúdo possa ser processado.4. Carregado o conteúdo do ficheiro, cada uma das milhares de linhas de log são processadas, nesta operação os IDs são substituídos por nomes fáceis de interpretar.
5. Por fim, os registos agora com informação enriquecida, são enviados para a DVP seleccionada.
Quer testar por si próprio?
Aqui tem um módulo Terraform para poder testar este exemplo (simplificado).
Considerações finais
Em conclusão, a solução apresentada permite uma abordagem de fácil utilização e flexível que não implica grandes conhecimentos prévios em Lambda, Python ou Step Functions.
- Permite um alto nível de segurança, os acessos aos bucket S3 são apenas e só autorizados ao Role que executa a função Lambda, limitando assim os potenciais riscos de acesso não autorizados.
- Controlo total sobre os custos. Redução do paralelismo de forma a controlar a taxa de ingestão dos dados. Mantendo o custo da DVP tão baixo quanto possível.
- A complexidade da solução permanece estável e de forma independente da quantidade de ficheiros processados.
-
Um dashboard permite manter a visibilidade sobre a execução, verificação do progresso em tempo real e detecção imediata de possíveis falhas.