Este artículo es parte de una serie de publicaciones sobre anti patrones en TDD. El primero capítulo cubrió: the liar, excessive setup, the giant and slow poke. En la industria, generalmente hablamos sobre cómo se deben hacer las cosas, pero a veces nos olvidamos cómo podemos aprender con los errores que cometemos al escribir pruebas unitarias.
Este blog es el segundo de la serie donde nos enfocaremos en cuatro anti patrones más, llamados: The mockery, The inspector, The generous leftovers y The local hero. Cada uno se centra en un aspecto específico del código que dificulta las pruebas.
Potencialmente, una de las causas principales por las que las empresas argumentan que no tienen el tiempo necesario para crear soluciones guiadas por pruebas.
Si lo prefieres puedes ver el contenido de este workshop en formato video aquí.
En la encuesta que llevamos a cabo, hemos preguntado: "La empresa en que trabajo o trabajé anteriormente argumentan que TDD requiere demasiado tiempo para terminar una tarea y los equipos no tienen tiempo para ello."
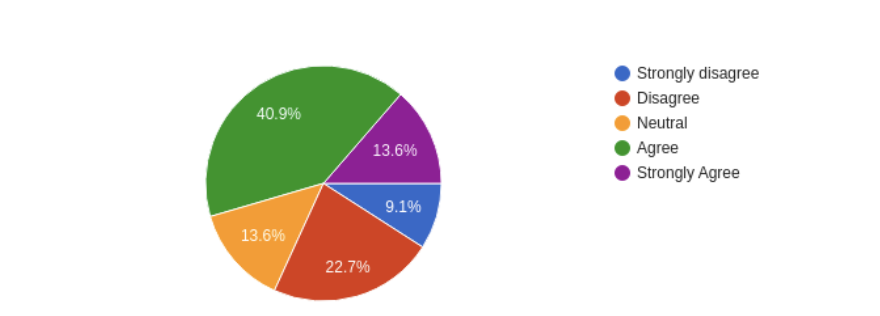
Más del 50% de los encuestados coincidieron en que en las empresas para las que han trabajado, se da la idea de que TDD requiere más tiempo para terminar una tarea.
Más del 50% de los encuestados coincidieron en que en las empresas para las que han trabajado, se da la idea de que TDD requiere más tiempo para terminar una tarea.
Se requeriría más investigación para evaluar por qué ese es el caso y por qué los participantes tienen esta percepción. Por lo tanto, incluso sin datos, podríamos inferir que, si enfrenta dificultades para escribir las pruebas o mantenerlas, tomará más tiempo. Por otro lado, la prevención de esas dificultades (anti patrones) podría ser una forma de integrar la cultura de prueba y evitar dicha percepción.
The mockery
The mockery es uno de los anti patrones más populares entre los desarrolladores, ya que parece que todo el mundo ha tenido alguna experiencia con mocking para hacer pruebas. La idea del mock es simple: evita la ejecución del código externo (librerías, APIs) para centrarse en lo que desea probar. Por lo tanto, mocking tiene su propia denominación y categorías que lo hacen único y, al mismo tiempo, es difícil de usar correctamente.
Por ejemplo, Martin Fowler y Uncle Bob, clasifican los mocks en diferentes tipos: dummies, spies, fakes y stubs. Uncle Bob se refiere a "True mocks" mientras que Martin Fowler se refiere a "Test double". Uncle Bob explica que los "mocks" se difundieron porque es más fácil decir: "I will mock that", "can you mock this"?
La diferencia entre ellos es importante y nosotros, como desarrolladores, tenemos la costumbre de denominar todo como "mock", engañando así a veces lo que queremos decir, spring.io va más allá, evitando el debate sobre si debemos usar mocks o no (refiriéndose a la Chicago School y London School del TDD) - este es un tema que merece una entrada de blog en sí misma. Martin Fowler también escribió sobre este tema y está de acuerdo en que
Por otro lado, the mockery se refiere a la misma definición que Uncle Bob, se refiere a todos los mocks. Para aclarar, dividamos el anti patrón en dos partes.
La primera, es el número excesivo de mocks necesarios para probar una clase (en este contexto, el mock, puede ser un dummy, un fake, un stub o spy). A medida que crece el número de mocks, aumenta la probabilidad de probar el mock en lugar del código deseado; también está relacionado con el excessive setup y es aquí donde comenzamos a ver alguna conexión entre los anti patrones.
La segunda parte es probar el mock en lugar de su interacción con el código cuando estamos haciendo pruebas. Veamos un ejemplo en el siguiente código, que es una interacción con una pasarela de pago.
/**
* Two constructor dependencies, both need to be
* mocked in order to test the process method.
*/
class PaymentService(
private val userRepository: UserRepository,
private val paymentGateway: PaymentGateway
) {
fun process(
user: User,
paymentDetails: PaymentDetails
): Boolean {
if (userRepository.exists(user)) {
return paymentGateway.pay(paymentDetails)
}
return false
}
}
With test:
class TestPaymentService {
private val userRepository: UserRepository = mockk()
private val paymentGateway: PaymentGateway = mockk()
private val paymentService = PaymentService(
userRepository,
paymentGateway
)
@Test
fun paymentServiceProcessPaymentForUser() {
val user: User = User()
every { userRepository.exists(any()) } returns true
every { paymentGateway.pay(any()) } returns true // setting up the return for the mock
assertTrue(paymentService.process(user, PaymentDetails())) // asserting the mock
}
}
En este ejemplo, PaymentGateway.kt, que se agrega con el objetivo de hacer una prueba, y lo que estamos probando es el retorno del mock, más qué ejecutando el código que depende del mismo.
Causas:
- ¿Razones históricas/estilos TDD?
- Tan simple como es el código, lo más fácil es usarlo en exceso
- Además, sin experiencia en TDD.
The inspector
A menudo el objetivo de las pruebas es mezclado con el hecho de inspeccionar, es decir no me centro en el comportamiento sino, en el hecho de cómo la clase está haciendo alguna acción, de momento me centraré en la idea de inspeccionar en lugar de verificar el comportamiento (la salida).
Por ejemplo, durante la prueba, se vuelve un poco más complicado, ya que nos gustaría verificar si, dada una entrada X, recibiremos el resultado Y, en el siguiente fragmento, está el método getFilesToWriteRelease y setFilesToWriteRelease.
Si pensamos en el contexto de la clase , ¿por qué existen estos métodos? ¿Deberían estar ahí?
<?php
/* skipped code */
class Assembly
{
/* skipped code */
public function __construct(
FindVersion $findVersion,
FileRepository $fileRepository,
string $branchName,
FilesToReleaseRepository $filesToReleaseRepository
) {
$this->findVersion = $findVersion;
$this->fileRepository = $fileRepository;
$this->branchName = $branchName;
$this->filesToReleaseRepository = $filesToReleaseRepository;
}
public function getFilesToWriteRelease(): array
{
return $this->filesToWriteRelease;
}
public function setFilesToWriteRelease(array $filesToWriteRelease)
{
$this->filesToWriteRelease = $filesToWriteRelease;
return $this;
}
public function packVersion(): Release
{
$filesToRelease = $this->getFilesToWriteRelease();
if (count($filesToRelease) === 0) {
throw new NoFilesToRelease();
}
$files = [];
/** @var File $file */
foreach ($filesToRelease as $file) {
$files[] = $this->fileRepository->findFile(
$this->findVersion->getProjectId(),
sprintf('%s%s', $file->getPath(), $file->getName()),
$this->branchName
);
}
$versionToRelease = $this->findVersion->versionToRelease();
$release = new Release();
$release->setProjectId($this->findVersion->getProjectId());
$release->setBranch($this->branchName);
$release->setVersion($versionToRelease);
$fileUpdater = new FilesUpdater(
$files, $release, $this->filesToReleaseRepository
);
$filesToRelease = $fileUpdater->makeRelease();
$release->setFiles($filesToRelease);
return $release;
}
}
En este sentido, si pensamos en la programación orientada a objetos, hablamos de invocar métodos en objetos. Tales invocaciones nos permiten interactuar y obtener resultados, pero en esta prueba el get/set está rompiendo la encapsulación solo en aras de la prueba. En el ejemplo, en otras palabras, estamos inspeccionando con el set/get y no comprobando el comportamiento.
Otra posible razón para experimentar con the inspector es empezar a engañar el código con la reflexión para testear una parte específica. Afortunadamente, hace unos años, nos hicieron esta pregunta en stackoverflow. ¿Es malo tener que usar la reflexión? Antes de continuar con esta pregunta, hagamos un resumen rápido de lo que es la reflection y por qué se usa en primer lugar.
Baeldung da algunos ejemplos de por qué podría necesitar reflexión, el uso principal es para comprender una parte determinada del código, cuáles son los métodos, cuáles son las propiedades y actuar sobre ellos. Veamos el siguiente ejemplo:
public class Employee {
private Integer id;
private String name;
}
@Test
public void whenNonPublicField_thenReflectionTestUtilsSetField() {
Employee employee = new Employee();
ReflectionTestUtils.setField(employee, "id", 1);
assertTrue(employee.getId().equals(1));
}
En este ejemplo, intentamos engañar el código sobreescribiendo su comportamiento que tiene el empleado id privado, para que sea público, y entonces definimos el id como 1.
Algunas suposiciones en las respuestas que apuntan al uso de reflection como una mala práctica:
1. La modificación del código de producción por el bien de las pruebas es una señal de que algo va mal en el diseño
2. El uso de reflection para lograr un x % de cobertura, a menudo apunta a problemas más profundos en la organización
Causas:
- Falta de práctica en TDD
- Orientado a la cobertura
The Generous leftovers
Mientras practicas TDD, tareas como por ejemplo configurar el estado en el que se ejecutará las pruebas es algo básico. Establecer fake data, listeners, autenticación, o lo que sea necesario, los definimos porque son cruciales para la prueba, pero a veces nos olvidamos de restablecer el estado para que sea como era antes de la prueba - la fase xUnit en la que ocurre dicha preparación es nombrada : "instalar, ejercitar, verificar, desmontar".
Esto puede causar diferentes problemas, y el primero es que falle en la siguiente prueba, que se suponía que debería funcionar sin problema. A continuación vemos una lista que intenta representar algunos escenarios en los que podría ocurrir.
1. Configurar listeners y olvidarse de eliminarlos, también podría causar pérdidas de memoria
2. Completar datos sin eliminarlos, como archivos, bases de datos o incluso caché
3. Dependiendo del test, se crean los datos necesarios y se usan en otro test.
4. Por último, pero no menos importante, cleaning up mocks
Si pensamos en el punto 3, dicho comportamiento será difuso al hacer la prueba; por ejemplo, el uso de datos persistentes es imprescindible para las pruebas end-2-end. Pero, por otro lado, el 4 es una fuente común de errores durante las pruebas guiadas por test. A menudo, como "the mock" se suele utilizar para recoger llamadas en el objeto (y verificarlo más tarde), es común olvidarse de restaurar su estado.
Codingwithhugo representa este comportamiento en un fragmento de código usando jest, dando el siguiente escenario de prueba (y suponiendo que están en el mismo ámbito):
const mockFn = jest.fn(); // setting up the mock
function fnUnderTest(args1) {
mockFn(args1);
}
test('Testing once', () => {
fnUnderTest('first-call');
expect(mockFn).toHaveBeenCalledWith('first-call');
expect(mockFn).toHaveBeenCalledTimes(1);
});
test('Testing twice', () => {
fnUnderTest('second-call');
expect(mockFn).toHaveBeenCalledWith('second-call');
expect(mockFn).toHaveBeenCalledTimes(1);
});
La primera prueba que llama a la función bajo el test pasará, pero la segunda fallará. La razón es no limpiar la ejecución del mock. La prueba falla apuntando que el mockFn fue llamado dos veces. Conseguir el flujo como debería es tan fácil como:
test('Testing twice', () => {
mockFn.mockClear(); // clears the previous execution
fnUnderTest('second-call');
expect(mockFn).toHaveBeenCalledWith('second-call');
expect(mockFn).toHaveBeenCalledTimes(1);
});
Los desarrolladores de javascript no afrontan fácilmente este comportamiento, ya que la naturaleza del alcance en javascript lo impide. De todos modos, tener en cuenta estos detalles puede marcar la diferencia al escribir las pruebas.
Sin tener en cuenta los detalles, contribuiría a la percepción de "tomar más tiempo para terminar una tarea" que vimos en la encuesta, una vez que este tipo de comportamiento es específico para el código de prueba.
Causas:
- Falta de práctica en TDD
- Mezclando diferentes tipos de pruebas, integration/unit/end-to-end
The local hero
Los anti patrones en TDD preceden a la era de los contenedores, en la que era común que hubiera diferencias entre el entorno del desarrollador y el servidor en el que realmente se ejecutaría la aplicación. A menudo, ya que no eran iguales, la configuración específica de la máquina del desarrollador se convertía en un problema en el camino durante el proceso de despliegue, lo que significa que se necesitaba un retrabajo para que el servidor tuviera la misma configuración que en la máquina del desarrollador.
PHP, por ejemplo, se basa en gran medida en extensiones que pueden o no habilitarse en el servidor (dónde se ejecuta el código). Extensiones como hilos, controladores para conectarse a una base de datos y muchos más.
En este caso, si el desarrollador confiara en una versión específica para una extensión dada, el test se ejecutaría con éxito, pero tan pronto como intentáramos ejecutar la suite en otra máquina, o en el servidor de integración continua que no tenga dicha configuración, fallaría.
No solo eso, las variables de entorno también pueden interferir. Por ejemplo, el siguiente código muestra un componente que necesita una URL para cargar la survey (parte del código se eliminó/modificó intencionalmente y se adaptó para ajustarse al ejemplo, para más información, haz click este enlace de github):
import { Component } from 'react';
import Button from '../../buttons/primary/Primary';
import '../../../../scss/shake-horizontal.scss';
import './survey.scss';
const config = {
surveyUrl: process.env.REACT_APP_SURVEY_URL || '',
}
const survey = config.surveyUrl;
const mapStateToProps = state => ({
user: state.userReducer.user,
});
export class Survey extends Component {
/* skipped code */
componentDidMount = () => { /* skipped code */}
onSurveyLoaded = () => { /* skipped code */}
skipSurvey = () => { /* skipped code */}
render() {
if (this.props.user.uid && survey) {
return (
<div className={`w-full ${this.props.className}`}>
{
this.state.loading &&
<div className="flex justify-center items-center text-white">
<h1>Loading...</h1>
</div>
}
<iframe
src={this.state.surveyUrl}
title="survey form"
onLoad={this.onSurveyLoaded}
/>
{
!this.state.loading && this.props.skip &&
<Button
className="block mt-5 m-auto"
description={this.state.buttonDescription}
onClick={this.skipSurvey}
/>
}
</div>
);
}
return (
<div className="flex justify-center items-center text-white">
<h1 className="shake-horizontal">Something wrong happened</h1>
</div>
);
}
}
/* skipped code */
Y aquí el test case para estos componentes:
import { mount } from 'enzyme';
import { Survey } from './Survey';
import { auth } from '../../../../pages/login/Auth';
import Button from '../../buttons/primary/Primary';
describe('Survey page', () => {
test('should show up message when survey url is not defined',() => {
const wrapper = mount(<Survey user= />);
const text = wrapper.find('h1').text();
expect(text).toEqual('Carregando questionário...');
});
test('should not load survey when user id is missing', () => {
const wrapper = mount(<Survey user= />);
const text = wrapper.find('h1').text();
expect(text).toEqual('Ocorreu um erro ao carregar o questionário');
});
test('load survey passing user id as a parameter in the query string', () => {
const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' };
const wrapper = mount(<Survey user={user} />);
const url = wrapper.find('iframe').prop('src');
expect(url.includes(auth.user.uid)).toBe(true);
});
test('should not up button when it is loading', () => {
const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' };
const wrapper = mount(<Survey user={user} />);
expect(wrapper.find(Button).length).toBe(0);
});
test('should not up button when skip prop is not set', () => {
const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' };
const wrapper = mount(<Survey user={user} />);
expect(wrapper.find(Button).length).toBe(0);
});
test('show up button when loading is done and skip prop is true', () => {
const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' };
const wrapper = mount(<Survey user={user} skip={true} />);
wrapper.setState({
loading: false
});
expect(wrapper.find(Button).length).toBe(1);
});
});
A pesar del tiempo que tiene el código (componentes de clase en reactjs), parece hacer el trabajo bastante bien. Al derivar el comportamiento de los casos de prueba, podemos entender que se está cargando algo en función de la URL de la encuesta y la identificación del usuario. Desafortunadamente, los detalles de la implementación son lo que más importa: si ejecutamos el caso de prueba para la implementación actual, fallará.
Conjuntos de test: 1 fallido, 62 aprobados, 63 en total
Test: 3 fallidas, 593 aprobadas, 596 en total
Y la solución para tal ejecución es exportar una variable de entorno
llamado REACT_APP_SURVEY_URL. Bueno, la solución fácil sería usar esta variable tal cuál, es decir, exportala en el servidor de integración o dónde sea la ejecución de las pruebas. La solución a largo plazo sería evitar depender en la definición externa y asumir algunos valores predeterminados, aquí están algunas ideas que me vienen a la cabeza para solucionarlo correctamente:
1. Asumir una variable ficticia como predeterminada
2. No utilizar ninguna URL y crear los test para tenerla o no; si no, simplemente omitir la ejecución
Otro ejemplo sería confiar en los ficheros que están en el sistema operativo, este problema también se analiza en stack overflow thread. El problema que surge en una prueba tan dependiente es que la prueba se ejecutaría solo en una máquina con Windows. Idealmente, las dependencias externas deben evitarse utilizando mocks.
Causas:
- Las dependencias utilizadas para el desarrollo no tienen en cuenta otros lugares para ejecutarse; esto también es un problema para las aplicaciones que no se crearon teniendo en cuenta la nube.
- Confiar en las dependencias del sistema operativo
- Depender del sistema de archivos
Consideraciones finales
En este segundo episodio, cubrimos cuatro antipatrones más que se interponen en nuestro camino mientras desarrollamos aplicaciones guiadas por pruebas. Cuando tales problemas llegan a la base del código, es normal percibir que las pruebas, "ralentizarán la entrega de una tarea en comparación con ninguna prueba". Pero, por otro lado, también puede ser un arma de doble filo, en la que no tener las pruebas podría ralentizarte aún más.
The mockery fue el anti patrón más popular, y las respuestas de la encuesta mostraron que el mal uso de los test doubles (o, más conocidos como mocks) puede ser una fuente de problemas. También vimos que la reflexión podría ser un problema mientras que probar y restablecer el estado es importante para mantener el conjunto de las pruebas nítido. Finalmente, cubrimos el problema en el que el conjunto de las pruebas solo se ejecuta en la máquina de los desarrolladores (o para el estándar actual, ¿en la imagen docker de los desarrolladores?).
En general, esperamos que esto se resuma con el episodio anterior y que mantenga su conjunto de pruebas funcionando sin problemas.



