El panorama tecnológico cambia constantemente, por eso a menudo vemos cómo algunas aplicaciones no resisten el paso del tiempo. Para contrarrestar este problema, podemos optar por ampliar, reconstruir y rediseñar las aplicaciones existentes.
A menudo, la solución propuesta es reconstruir el sistema legacy. Aunque esta sea la solución soñada de un desarrollador, es muy poco práctica y costosa en términos de tiempo y dinero.
Hay que tener en cuenta que los contenedores ya no son de última tecnología, y su valor ha sido ampliamente aceptado. La contenerización puede contribuir a la modernización de sistemas mediante la actualización de la tecnología subyacente.
En este artículo exploro la refactorización/re-arquitectura como solución evolutiva capaz de sustentar necesidades presentes y futuras.
Para empezar, veamos las ventajas y retos de los contenedores, los problemas que resuelven y los que no.
Ventajas
- Los contenedores ofrecen mayor portabilidad.
- Los contenedores pueden proporcionar la base para la arquitectura de microservicios. Cabe destacar que, aunque es fácil confundir las aplicaciones en contenedores con microservicios, estos no son lo mismo.
- Los contenedores resuelven el problema de que la aplicación funcione únicamente en tu ordenador. Permiten que funcione en el sistema de un desarrollador, así como en el runtime de producción de otro desarrollador con una modificación mínima o nula.
- Los contenedores pueden encapsular todas las dependencias que necesita una aplicación en un paquete limpio y ordenado.
- Le permiten a los desarrolladores colaborar con los ingenieros de sistemas escribiendo archivos IAC, como lo es un Dockerfile.
- Los contenedores nos permiten testear los cambios más rápidamente sin preocuparnos por el resto de la infraestructura.
- La automatización de los despliegues es más fácil.
- El escalado horizontal es mucho más fácil.
- El despliegue es más rápido.
- Permite ver y manejar mejor la seguridad del paquete de aplicaciones.
Retos
- Para aprovechar eficazmente la contenerización se deben realizar cambios operativos.
- Los contenedores no funcionan a velocidades bare-metal.
- No es posible ejecutar un contenedor Linux en Windows o viceversa.
- Los contenedores no pueden ejecutar aplicaciones gráficas como las desktop apps.
¿Deberían todas las aplicaciones ser contenerizadas?
No todas las aplicaciones son adecuadas para la nube y no todas las aplicaciones son adecuadas para la contenerización. Algunos ejemplos de candidatos poco adecuados son:
- Las aplicaciones obsoletas construidas con lenguajes o tecnologías propietarias. Piensa en apps que dependan de una característica específica de hardware, como los mainframes. Podría ser más económico reconstruirlas en la nube.
- Las aplicaciones que requieran una reestructuración completa. Convertir tu aplicación legacy en una infraestructura de microservicios requiere un replanteamiento completo de su estructura. No todos los departamentos de IT tendrán el presupuesto, los recursos o el tiempo para hacer esto.
Sin más preámbulos, veamos qué debemos evaluar para contenerizar aplicaciones existentes.
¿Cómo puedo empezar?
Imaginemos que la aplicación que te gustaría ejecutar en contenedores es una aplicación legacy monolítica. Esta aplicación tiene algunos procesos de fondo en forma de cron jobs de Linux y utiliza una única base de datos relacional como back-end. La siguiente lista no es exhaustiva, pero debería darte suficientes ideas para planificar tus cambios.
Planifica la contenerización
En primer lugar, la estrategia de contenerización se debe basar en las necesidades de tus aplicaciones. Existen varias soluciones para desplegar una aplicación legacy en un contenedor:
- Reescribe y rediseña tu aplicación legacy.
- Ejecuta una aplicación monolítica ya existente dentro de un único contenedor.
- Refactoriza tu aplicación para aprovechar la nueva arquitectura distribuida.
Independientemente del método que elijas, es esencial determinar si la aplicación es adecuada para la contenerización.
A la hora de elaborar el plan, hay que tener en cuenta la evolución futura de la arquitectura, su rendimiento y seguridad.
También podemos utilizar un diagrama de arquitectura de aplicación. Si no tienes uno, dedica tiempo a crearlo. Además de ser valioso a largo plazo, este diagrama ayuda a identificar las tecnologías / librerías compartidas entre las aplicaciones seleccionadas para la contenerización.
Si tienes numerosas aplicaciones que utilizan librerías, versiones de lenguaje, servidores web y sistemas operativos similares, entonces todos estos elementos pueden ser combinados en una imagen base que cada aplicación pueda usar como punto de partida.
Tómate el tiempo necesario para revisar las configuraciones o limitaciones del sistema.
Por ejemplo, recientemente contenerice mi aplicación web y ocurrió un error. Esto sucedió cuando intentaba subir un archivo más grande de lo permitido en la configuración del servidor web.
Ver las configuraciones del lenguaje y del entorno informático ayuda.
Identifica sus dependencias
Antes de empezar a refactorizar, es imprescindible analizar las dependencias de tu aplicación y del sistema operativo. Por ejemplo, puede que necesites librerías de sistema operativo, como libzip, si tu lenguaje no puede proporcionarlas como parte de las librerías estándar.
Si no puedes permitirte el lujo de tener estos paquetes de gestión de archivos, siempre puedes hacer un grep en el codebase para encontrar cualquier importación que revele el uso de librerías de terceros.
Variables de entorno
Busca los lugares en los que se usen variables de entorno. He visto que se utilizan para suministrar distintos tipos de información como claves de API, endpoints, rutas o entornos de aplicaciones.
Las credenciales y las claves API pueden trasladarse a un gestor de secretos seguro que se integre con el runtime del contenedor elegido.
Refactorización
No todas las aplicaciones se construyen con un conjunto adecuado de opciones para contenedores. Cuando esto sucede, se deben refactorizar partes de la aplicación. Una de las cosas que siempre hay que revisar son las configuraciones; como los ajustes por entorno.
También hay que tener en cuenta que cualquier clase que escriba datos a rutas locales del sistema operativo tendrá que ser cambiada a una solución de almacenamiento más distribuida.
Incorpora pruebas de aceptación, si no las tenías antes. Esto garantizará que, a medida que empieces a introducir cambios, la aplicación continúe a funcionar correctamente.
Utiliza feature flags si estás considerando usar la aplicación en tu entorno actual mientras realizas la refactorización.
Esta técnica te dará cierta flexibilidad y seguridad.
Imágenes base
Imagina que construyes tu aplicación basándote en una imagen docker que encontraste en algún sitio. Tenía todas las características que necesitabas. Pero un exploit de seguridad hizo que tu aplicación dejará de funcionar después de haberla creado basándote en esa imagen.
Otro ejemplo sería cuando la imagen base elegida ya no está disponible. Por lo que, cuando lanzas tu aplicación nuevamente, el proceso de construcción parece estar roto.
Para evitar estos problemas, siempre que sea posible, utiliza las imágenes oficiales del lenguaje y la versión de Linux (u otro sistema operativo) más parecida.
Por ejemplo, si tiene una aplicación PHP 7.2 que se ejecuta en Ubuntu 21.04 LTS, estaría bien utilizar una imagen base de Debian bullseye.
Posibles obstáculos
Ya tienes una idea de los tipos de retos a los que puedes enfrentarte. Sin embargo, veamos algunos factores adicionales que pueden convertirse en obstáculos si no se planifican bien.
Opciones de almacenamiento de datos
Es imprescindible evaluar tu aplicación para saber dónde almacena sus datos. Esto es importante debido a ciertas condiciones específicas requeridas por algunos sistemas operativos. Veamos dos casos de uso:
- Tu aplicación mantiene sesiones web file-based en algún almacenamiento temporal. Esto puede no parecer un problema, especialmente cuando estás ejecutando sólo una instancia de la aplicación. El tamaño del almacenamiento puede que tampoco sea un problema, hasta que la aplicación comience a escalar, tenga múltiples instancias ejecutándose, y haga que tus visitantes aterricen en contenedores sin sesión web almacenada.
- Si la aplicación tiene contenido estático subido por los usuarios, tendríamos que mover estos contenidos al almacenamiento compartido o migrarlos al almacenamiento object-based. De este modo, cuando escales horizontalmente, leerás y escribirás en un solo lugar.
En estos dos escenarios, el elemento común es la necesidad de averiguar cómo darle forma a los datos. Esto puede generar más trabajo de migración de datos a un almacenamiento compartido.
Terminación de SSL
Como SSL/TLS se utiliza prácticamente en todas partes, es fundamental resolver este aspecto cuando el proceso esté más avanzado. Esto puede no ser un problema inicialmente, sobre todo cuando se ejecuta sólo una instancia de un contenedor.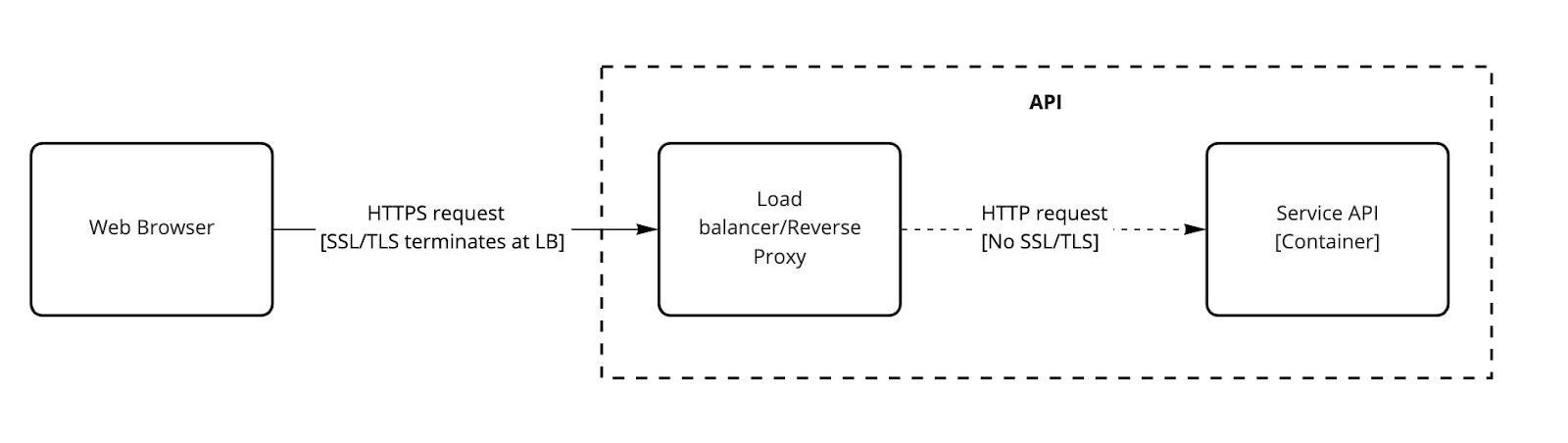
La configuración de este diagrama es bastante típico en un entorno contenerizado: el SSL/TLS termina en el límite (por ejemplo, en un equilibrador de carga) y el tráfico se mueve dentro de la red interna de confianza, pero sin estar encriptado.
Esto ahora se convierte en un problema porque si la aplicación establece cookies seguras, que debería, no se transmitirán al navegador porque llegan a través de HTTP.
Cron Jobs
Los contenedores deben llevar a cabo un solo trabajo muy bien. Cuando vemos las diversas tareas que una aplicación típica realiza en segundo plano, los cron jobs son muy útiles. Se centran en hacer una sola cosa a la vez. Sin embargo, se debe evitar sobre cargar de cron jobs un contenedor que también sea un servidor web.
Debemos ejecutar sólo un proceso por contenedor. De lo contrario, el proceso que se bifurca y se ejecuta en segundo plano no es monitorizado y puede detenerse sin que lo sepamos.
Comparemos algunos enfoques.
Usa el crontab del host
Aunque no sea una opción de gran escala, usar el crontab de la máquina anfitriona permite crear tareas agendadas. Además, como los cron jobs también permiten ejecutar comandos, puedes utilizar el motor del contenedor como lo harías con una línea de comandos. Esto se hace utilizando el mismo contenedor de tu aplicación web pero anulando el comando ENTRYPOINT.

Según este ejemplo, tu contenedor se recrearía cada 10 minutos y se eliminaría después de la ejecución.
Aquí hay algunos pros y contras. Por ejemplo, no tendrás que preocuparte de reiniciar los contenedores de Docker. Tampoco tendrás que gestionar el registro y, por lo tanto, eliminarás el ruido que genera. Sin embargo, no es recomendable utilizar los recursos de un host, ya que las tareas en segundo plano pueden ser bastante pesadas (ej. la generación de informes). Además, esto puede no ser una opción si tu runtime objetivo es un entorno serverless donde no tienes acceso al host subyacente.
Usa cron incrustado en tus contenedores
Esto es ideal para servicios simples ya que empaquetar los archivos de crontab directamente en tus servicios de contenedor ofrece portabilidad.
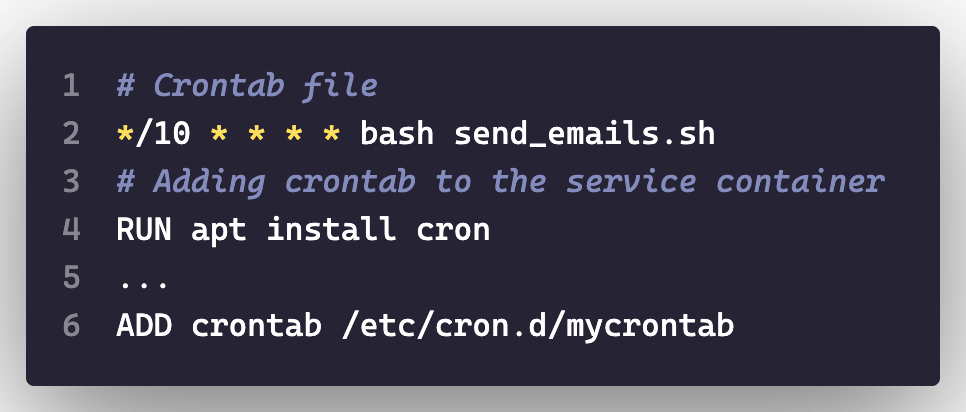
De esta manera podemos escalar nuestra aplicación más fácilmente, debido a que ya no dependería de la máquina anfitriona. Sin embargo, ten en cuenta que escalar el número de contenedores puede tener serias implicaciones si el trabajo de fondo no se ocupa del procesamiento concurrente.
Además, nos desvía del principio de hacer bien una cosa.
Separa cron del servicio de tu aplicación
Para este enfoque, la imagen de tu aplicación debe ser la base de ambos contenedores. Ambos contenedores necesitarán acceso al volumen y a la red del servicio. Lo único que cambia para el contenedor es el proceso en primer plano.

En este ejemplo, utilizamos la misma imagen de la aplicación, pero anulamos el comando ENTRYPOINT. A este punto, la programación de tareas se puede hacer de acuerdo a tu runtime objetivo.
Permisos de archivo
Este problema tiene dos vertientes. Por un lado, hay archivos creados dentro de los contenedores con sus respectivos permisos. Por otro, cuando se construyen las imágenes de los contenedores primero, los permisos de los archivos pueden ser demasiado permisivos.
Los permisos y el ownership de los archivos se copian del sistema de archivos del host mientras se construyen las imágenes.
Por lo tanto, sé cuidadoso al construirlos en entornos que implementan el principio de mínimo privilegio en el sistema de archivos. La mayoría de los servidores CI tendrán permisos restringidos.
De este modo, cuando copias o añades archivos en un Dockerfile, puedes especificar lo siguiente:

No utilices el usuario root por defecto, ya que puede causar problemas con los permisos y riesgos de seguridad.
La forma más eficaz de prevenir los ataques de escalada de privilegios dentro de un contenedor es configurar sus aplicaciones para que se ejecuten como usuarios sin privilegios.
Secretos
Extrae cualquier secreto, como las API keys del gestor de secretos que ofrece tu runtime objetivo. Inicialmente, es posible que no necesites un gestor de secretos, por lo que moverlos a las variables de entorno te permitirá seguir con el trabajo en cuestión.
Optimización de Imagen
Una obsesión común, que he notado, es tratar de tener las imágenes de los contenedores lo más pequeñas posible. Por ejemplo, tu aplicación actual en Debian ocupa 500MB, mientras que la misma aplicación empaquetada con Alpine Linux ocupa 50MB.
Creo que perseguir esta obsesión puede ser una trampa, ya que no todos en tu equipo pueden estar familiarizados con Alpine en lugar de Debian. Además, pueden haber diferencias entre las librerías consideradas esenciales para la funcionalidad de tu aplicación. Sin embargo, dicho esto, los contenedores te permiten experimentar con este tipo de cosas de manera mucho más segura. Al principio este no debería ser el objetivo, pero podría ser algo que hagas una vez que estés acostumbrado.
Escalado horizontal
Aunque esta es la gran ventaja de la contenerización, implica posibles retos. Por ejemplo, la consistencia de los datos y la coordinación de las tareas puede ser un reto en múltiples instancias. Como resultado, para que se produzca esa coordinación, los costes pueden ser más altos y más código puede ser necesario. Además, los servidores subyacentes pueden seguir encontrando problemas de límites de hardware si las máquinas anfitrionas no tienen las especificaciones adecuadas.
Logging
La práctica preferida para contenerizar es escribir los contenedores en la salida estándar, por lo que probablemente esto será distinto a escribir registros en un archivo específico del sistema operativo. Esto te permitirá ver varios servicios conjuntamente, aunque querrás diferenciar entre los registros de cada servicio. Se necesitaría una solución de registro centralizada para ayudar con la agregación de varios registros cuando escales. Como resultado de esto, podrá ser necesario refactorizar la configuración de tu log-driver.
Seguridad
Antes de desplegar nuestro contenedor, debemos ser completamente conscientes de lo que ocurre en su interior. Siguiendo las prácticas recomendadas se pueden reducir la mayoría de los riesgos de seguridad. La lista de buenas prácticas es larga, así que veamos algunas de las cosas que hay que hacer y evitar:
- Cualquier cambio en la imagen o en el codebase debería generar un escaneo de pipeline de CI/CD. Hay muchas herramientas que nos ayudan a proteger los contenedores que pueden ser aprovechadas para esto. También debemos estar atentos a cualquier parche de seguridad que se publique.
- Debemos asegurarnos de aplicar el principio de mínimo privilegio cuando construyamos imágenes, y crear usuarios que no sean root con los permisos que basten. Como se mencionó anteriormente, también debemos utilizar imágenes de confianza provenientes de fuentes oficiales, como por ejemplo las imágenes oficiales de Python.
- Debemos construir controles de salud en los contenedores.
- Utiliza las instrucciones de COPY, en lugar de las de ADD, cuando construyas contenedores. ADD permite incluir archivos remotos.
- No almacenes ningún secreto, como claves de API u otras credenciales, en el contenedor. Utiliza un gestor de secretos establecido que pueda proporcionar secretos durante runtime.
- Dependiendo de cómo elijas ejecutar los contenedores, puede que también necesites asegurar tu entorno de ejecución.
- Haz que tu contenedor sea inmutable para eliminar la necesidad de SSH o shell.
- Elimina los editores como vi, nano.
- Monta sistemas de archivos read-only. Pero si tu contenedor pretende gestionar cargas de archivos, será mejor usar un servicio de almacenamiento en la nube.
Además de todo esto, deberías considerar el uso de una buena herramienta de escaneo de imágenes que te notifique la presencia de vulnerabilidades de seguridad a medida que la descubra.
Recapitulación
En resumen, en este artículo analizamos el enfoque de refactorización/rearquitectura de los contenedores, independientemente de la tecnología utilizada. También examinamos las ventajas y las dificultades de usar contenedores debido a su naturaleza efímera y stateless.
La lista de acciones que puedes tomar para planificar la migración y mejorar tu stack puede ser mucho más extensa y detallada. Esperamos que este artículo te haya ayudado a reconocer algunos de los principales problemas y te haya proporcionado algunos consejos útiles.
Posiblemente también querrás evaluar los distintos runtime a tu disposición, como Docker Swarm, Kubernetes, AWS Fargate, etc. Cada uno de ellos tendrá su propio conjunto de desafíos.
Si te gustaría saber más sobre refactorización, te recomendamos el blog de James Mason: Refactoriza antes de reescribir.



