Es posible que encuentres software que no puede ser testeado fácilmente, y con esto me refiero a programas que no fueron testeados desde el inicio. Puede que incluso hayas intentado hacerlo y hayas fallado en el intento. Pero no te preocupes, el software que no se diseña para ser testeado jamás será tan fácilmente comprobable como el que sí.
En este post, exploro cómo abordar las pruebas de software cuando el test es una ocurrencia de último minuto. Para hacerlo, explico el contexto a tomar en cuenta y muestro un ejemplo sencillo de Golden Master Testing y una implementación no estándar del patrón Golden Master.
También comparto un ejemplo práctico de cómo abordamos este reto con uno de nuestros clientes y los resultados que obtuvimos.
¿Por dónde empezar cuando se trabaja con un código que no se creó para ser probado?
Como consultoría de software, Codurance trabaja con muchos clientes y códigos que se encuentran en distintas etapas o estados. En el caso que comparto hoy, estábamos trabajando con un cliente que tenía un código de producción con pocas o ninguna prueba automatizada.
En primer lugar, fue fundamental establecer una "garantía" en la que un conjunto de pruebas automatizadas proporcionasen feedback sobre si los cambios en el código de producción alteraban su comportamiento.
Recibir este tipo de información en una fase temprana es importante, sobre todo cuando se depende de pruebas manuales que producen información lentamente. En este caso, era posible que el desarrollador no recibiese el feedback sino hasta horas, días o semanas después de realizar un cambio.
Características del legacy code que dificultan las pruebas
El código de producción de nuestro cliente tenía una serie de características típicas de un software escrito años atrás y que fue ampliado con el tiempo. Es importante tener en cuenta esto para entender mejor cómo tomamos las decisiones.
Estás son algunas de esas características, y otros datos pertinentes, que nos ayudaron a formular nuestra solución.
Dependencia en la base de datos
La parte del código que estábamos probando dependía en gran medida de la base de datos (BD), por lo que se ejecutaba en un horario determinado y consultaba a la BD los inputs a procesar. De esta manera, la BD proporcionaba el input al código en cuestión. Esto significaba que teníamos que proporcionar el input a la BD, pero hablaré sobre esto más adelante.
Debido al diseño del sistema, la base de datos era una parte integral de la ejecución del código de producción. Por ejemplo, controlaba qué ramas del código se ejecutaban. No es difícil ver la conexión entre esta afirmación y el impacto en la forma de testear el software. Si crees que tendremos que colocar muchos datos en la base de datos antes de invocar el código de producción, estas en lo correcto.
A continuación hablo del output - usando el término vagamente. Digo esto porque el código de producción procesa el input y envía los datos a la BD, y aquí me referiré a esto como "output" aunque no lo sea. Pero no quiero quedar atrapado en un debate filosófico sobre si eso es realmente un "input" a la BD. Así que, para resumir ese último punto, el comportamiento observable de esta parte del sistema está en examinar el efecto en la BD después de que el código de producción se haya completado.
Codebase extensa que ha crecido con el tiempo
El código es extenso y se ha ampliado con el tiempo. Lo digo de esa manera deliberadamente, ya que el diseño no necesariamente ha evolucionado pero si se ha añadido nuevo código a lo largo de todo el código existente. De este modo, lo que queda es grande y complejo, con algunas clases y métodos muy amplios.
Aquí, el tamaño del código es importante, ya que en este caso más código significaba más posibles ramas (ejecución de código, nada que ver con Git). Y, debido a su magnitud, podías hacer un cambio en la línea 2.000, y terminar impactando algo en la línea 10.000.
Todo esto significa que, como originalmente el código no se diseñó para ser testeado, no podíamos emplear técnicas que normalmente utilizaríamos, ya que muy probablemente generaría ciertos cambios en el amplio y complejo código subyacente. De hecho, hacerlo en ausencia de la "garantía" haría que esos cambios fueran potencialmente de alto riesgo, lo que era extremadamente indeseable en este dominio.
Código antiguo (que no ha envejecido bien)
Otra aspecto importante del contexto es la antigüedad del código. Sabemos que no es habitual que un software envejezca tan bien como, por ejemplo, el vino o el queso. Y cuando hablamos de "código legacy", no apreciamos el legado que han dejado quienes nos preceden.
Como mencione anteriormente, a lo largo de los años se había añadido código nuevo, por lo que muy probablemente este contenía ramas muertas. Esto es extremadamente importante, ya que es la razón por la cual, además de pedir a expertos en la materia que clasificaran el comportamiento y ejemplos de fuentes que lo testearan, solicitamos datos de producción como inputs.
El contexto y el entorno son fundamentales para habilitar pruebas en código legacy
Tal vez ya te diste cuenta de que esta no era una situación ideal para realizar pruebas Golden Master. Tuvimos que trabajar de forma iterativa para encontrar una solución, basándonos en el estudio del entorno y absorbiendo todo el contexto y los hechos. Pero primero hagamos un repaso de las pruebas Golden Master.
Qué hacer cuando no se pueden utilizar las pruebas estándar de Golden Master
Antes de entrar en detalles sobre este enfoque y nuestra solución, pensé que valdría la pena hacer un pequeño repaso del Golden Master Testing a través de un ejemplo sencillo.
Golden Master Testing - un rápido repaso
Aquellos que estén más familiarizados con la técnica del Golden Master, típicamente leerán cosas como esta:
Registra los outputs de un conjunto dado de inputs
Esto es muy sencillo, y si los has escrito tú mismo, probablemente ya tendrías un archivo con los inputs y otro con todos los outputs.

Tu input podría verse así:
1 Name: Sam, Age: 105
2 Name: Bob, Age: 34
3 Name: Linda, Age: 26
y el output así:
1 Can retire: true
2 Can retire: false
3 Can retire: false
Es sencillo, y cada línea se correlaciona con un único escenario. Por ejemplo, si el código de producción selecciona Sam y él tiene 105 años, entonces el código dirá que puede jubilarse.
A todos nos gustan los códigos sencillos y la simplicidad de lo apenas mostrado, pero en nuestro caso no podíamos darnos el lujo de escribir una implementación tan sencilla. No obstante, quisimos evaluar si un enfoque Golden Master realmente funcionaría y, sobre todo, si valdría la pena la inversión.
En el contexto de nuestro cliente, este enfoque era demasiado simple para funcionar. En su lugar, tuvimos que aplicar un enfoque personalizado que empezó con pruebas manuales.
Empieza por experimentar con una prueba manual
Nosotros empezamos escribiendo una primera prueba a mano. Esto es comparable a una sola línea del archivo anteriormente mencionado, que suele corresponder a un único escenario. Sin embargo, a diferencia del ejemplo descrito, nuestro código no era de una sola línea. Para este caso en concreto, necesitábamos configurar varias tablas de la base de datos que debían ser insertadas en un orden específico. Esto requería una orquestación cuidadosa dadas las restricciones de la base de datos.
Se trata del equivalente a tantear el terreno, y era necesario para obtener información sobre nuestro enfoque. Durante este experimento, llegamos a la conclusión (entre otras cosas) de que estas pruebas eran lentas de escribir, por lo que decidimos explorar si había una manera mejor.
Hipótesis, oportunidades y experimentos
Es posible que te hayan aconsejado no automatizar inmediatamente. Es un consejo sensato. Nosotros lo seguíamos cuando empezamos a escribir las pruebas manualmente. Como mencione, había una serie de tablas que teníamos que configurar antes de invocar el código de producción. Y nosotros nos dimos cuenta de que gran parte de esa configuración se podía hacer a partir del input del código de producción.
Así que nos preguntamos:
¿Podríamos crear pruebas utilizando el input para la configuración requerida?
Si lográbamos hacerlo, nos ahorrariamos el laborioso trabajo de crear la configuración a partir de la información del input, una y otra vez, para cada escenario. Imagínate leer un trozo de papel y luego introducir a mano parte de esa información a un ordenador. Así es como se sentía.
Experimentamos y descubrimos que este enfoque de crear automáticamente la configuración a partir del input era prometedor. Así que apostamos por este camino y continuamos con nuestro recorrido.
Una solución automatizada y más inteligente
Decidimos registrar lo que hacía el código de producción para ver qué efecto tenía sobre la BD. Como en nuestro contexto la base de datos era esencial, parecía perfectamente razonable hacerlo.
Esto significaría que ejecutaríamos el código de producción con cada input para capturar lo que ocurría en la base de datos (es decir, los efectos secundarios).
Ejemplo de testing de un código legacy que depende de una BD
A continuación explico lo que hicimos para probar el código legacy capturando los cambios en la base de datos.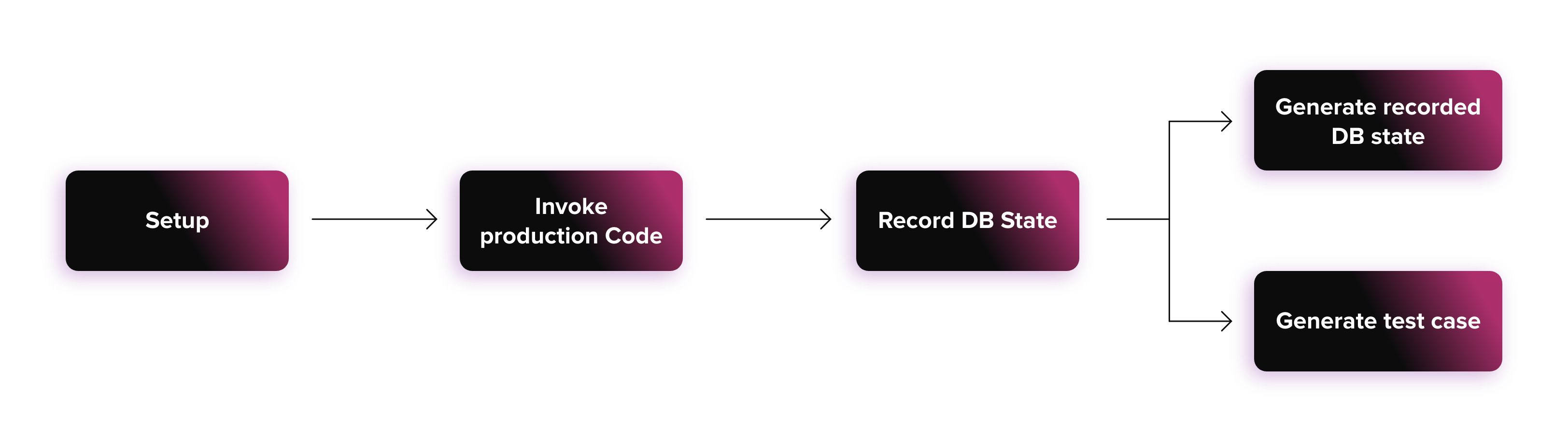
Este esquema presenta una imagen muy simplificada de cómo se captura el comportamiento del código de producción y cómo se generan las pruebas.
Profundicemos con más detalle lo que se hace en cada uno de estos pasos.
Configuración
Objetivo - configurar el "mundo" para que el código de producción se ejecute de manera esperada.
Ejemplos - añadir datos en la base de datos, aprovisionar un servidor mock FTP.
Invocar el Código de Producción
Objetivo - activar parte del código de producción, de forma que sea representativo de cómo se utiliza en producción.
Ejemplos - nombra el método runSomething() en la clase llamada TheLegacyCode
Registra el estado de la BD
Objetivo - identifica las tablas en las que se escribió y captura su contenido
Este paso es bastante específico y puede asumir distintas formas. He puesto un ejemplo concreto para simplificar las cosas.
Genera el estado registrado de la BD
Objetivo - almacena el estado de la BD después de invocar el código de producción. Esto constituye la base de las aserciones que se utilizan para comprobar si el estado de la BD cambia cuando se ejecutan los casos de prueba.
Genera casos de prueba
Objetivo - genera un archivo que represente una prueba y tenga toda la información necesaria para localizar el input y el output esperado (siempre usando este término vagamente) para un escenario específico.
Un código legacy complejo, de gran tamaño y dependiente de bases de datos también puede ser testeado
Antes de que añadiéramos este conjunto de pruebas, probablemente muchos dijeron "este código no se puede probar". Sin embargo, demostramos que sí se puede y, asimismo, ofrecimos una alternativa a quienes se encuentran en una situación similar.
También descubrimos que el enfoque que adoptamos tenía varias ventajas:
Feedback más rápido
Como lo ha indicado muchas veces la literatura, siempre es deseable obtener un feedback más rápido, y este conjunto de pruebas lo consiguio.
La cantidad de tiempo que se ahorra es realmente impresionante. Un evaluador manual tarda 2,5 horas en ejecutar 10 pruebas manuales, mientras que sólo tarda un minuto en ejecutar 10 versiones automatizadas de esas mismas pruebas. Esto se aprecia aún más si se tiene en cuenta que el conjunto de pruebas consta de unas 1.000 pruebas, y que ejecutarlas manualmente llevaría 10,5 días (para una persona que trabaje 24 horas al día), mientras que las pruebas automatizadas se completarían en 1 h 40 m.
El tiempo ahorrado es bastante, pero las pruebas automatizadas también le ofrecen mayor flexibilidad a los developers de ejecutar pruebas cuando lo deseen. Desafortunadamente, no se puede hacer lo mismo con un tester manual (tocar tres veces el teclado y hacer que aparezcan).
Mayor flexibilidad
Nuestra manera de generar estas pruebas nos permitió pivotar mucho más rápido que creándolas manualmente. Por ejemplo, si necesitábamos hacer una aserción sobre una tabla hasta entonces desconocida, podíamos configurarla en la herramienta y, sucesivamente, regenerar todas las pruebas (en las cuales la nueva tabla se almacenaría en el "estado registrado de la BD"). Esto fue muy útil, especialmente ya que, al no contar con toda la información necesaria, nos permitió ampliar nuestras pruebas a medida que aumentaba nuestro conocimiento.
Oportunidad de automatizar
Puede parecer obvio, pero esta fue una de las primeras instancias en las que este código tuvo algún tipo de pruebas automatizadas. En concreto, estas pruebas iban directamente al corazón de esta parte del sistema y probaban la lógica central, algo que no había ocurrido antes.
Prueba el código legacy con más confianza
Encontramos una manera de trabajar de forma iterativa para establecer un conjunto de pruebas Golden Master como medio para cambiar el código subyacente con más confianza y eliminar el miedo que puede formarse. De hecho, el cliente nos comentó cómo el miedo que originalmente tenía se había disipado.
Una cosa importante que hay que destacar es que, después de establecer un conjunto Golden Master, se puede empezar a modernizar la base de código legacy con confianza.
A medida que empieces a modernizar el codebase y a añadir pruebas más abajo en la pirámide (por ejemplo, pruebas unitarias), conseguirás una respuesta más rápida y dependerás menos de las pruebas Golden Master.
Como siempre, el contexto es importante y espero que entiendas que todas las técnicas tienen su momento y su lugar, e incluso la forma de aplicarlas dependerá considerablemente del contexto.
Compartir conocimiento es importante, y nos encantaría conocer tu experiencia con las pruebas de código legacy.



