Why is Monolith a Dirty Word?
First of all, let’s be clear in what we mean by “Monolith”. We are primarily talking about a software application that is deployed as a single artefact where the source code resides in a single repository. The application likely exposes several different business capabilities. For example, perhaps it has the ability to manage stock levels as well as taking payments for customer purchases and providing reporting functionality. There’s nothing inherently wrong with this so far. And in fact, as we’ll discuss later in this article, there is a lot to be said for this setup. However, “Monolith'' is often seen as a dirty word in the software development industry. The reason for this is that the majority of monoliths are poorly structured. As a result, they become hard to change because changes must span many different areas of the codebase. Over time, as more and more changes are added (even new capabilities), the complexity of the codebase increases and the Monolith becomes a real problem for the Organisation as it becomes harder to ship new features to its customers. At this point, many teams would call for the need to completely rewrite the application. This article suggests that doesn’t have to be the only approach.

The Modular Monolith
As I mentioned in the previous paragraph, many monolithic software applications are poorly structured. We want our software applications to be highly cohesive and loosely coupled. Most monoliths, unfortunately, fail in both of these categories and it's this that gives the Monolith a bad name. For example, we want to keep together those components that tend to change together. But many teams, unfortunately, have fallen into the trap of jumbling up all sorts of different components together. For example database access might be made directly from User Interface components. Brian Foote and Joseph Yeder wrote about software systems that had evolved in this way in their 1997 paper “Big Ball of Mud” where the title of the paper was used to describe monolithic systems which lacked any real structure.
“A Big Ball Of Mud is haphazardly structured, sprawling, sloppy, duct-tape and bailing wire, spaghetti code jungle.”
The below image illustrates this analogy. It is a dependency graph for one codebase. As you can see, the dependencies between components, and the level of coupling, has gone way beyond generally acceptable levels and this codebase would have been very difficult to change and maintain in that state.

Sadly, there are many monolithic codebases that fall into this category. It doesn’t have to be that way though and by applying good Domain-Driven-Design principles along with software craftsmanship practices we can achieve a well structured monolith, or as I like to call it a “Modular Monolith”. For me, this is the first step in thinking about breaking down any monolithic codebase, even if the longer term ambition is to move towards MicroServices, i.e a distributed systems architecture. Simon Brown has a great quote which I really like -
“If you can't build a monolith, what makes you think microservices are the answer?”
This, I believe came as a reaction to large numbers of software development teams wanting to adopt a MicroServices architecture even though their current architecture was akin to the “Big Ball Of Mud” architecture. Simon’s point is that MicroServices are not a “silver bullet” and you cannot shortcut applying good structure and design to your codebases. Furthermore, MicroServices architectures do not eliminate complexity. Instead, they shift that complexity from an application codebase level to infrastructure and coordination - in particular deployments, monitoring, observability and testing. These are often areas that tend to be less well understood in Organisations looking to adopt MicroServices for the first time. Martin Fowler talks about this in one of his articles, where he uses the term “Microservices Premium”.
Identifying Bounded Contexts
The question of course then is - where do we start if we want to restructure our monolithic codebase? Michael Feathers discussed the concept of a “seam” in his book Working Effectively With Legacy Code. A Seam is a portion of code that can be treated in isolation and, as a result, can be worked on without impacting the rest of the codebase. Michael’s primary usage of “seams” in his book was to help in cleaning up a codebase. But they are also good starting points for identifying Bounded Contexts. Bounded contexts are a key part of Domain-Driven Design. They represent cohesive and yet loosely coupled boundaries with an Organisation. So our first step needs to be identifying those seams in our codebase.
A good Bounded Context should model some capability that is provided to the rest of the Organisation and feeds into the wider Value Stream. EventStorming workshops can be a great first step in doing this as they allow for the full domain to be mapped out which can then be organised into Bounded Contexts.
Most programming languages provide mechanisms for grouping related pieces of code together, such as namespaces and packages. We can use these mechanisms to help model the Bounded Contexts in our codebase. If this is done correctly, at a high-level the structure of a codebase will reflect the various Bounded Contexts that exist in the domain.
Let’s consider an example of an e-commerce system. We have identified the following Bounded Contexts:
-
Payment (Responsible for processing customer payments for orders)
-
Product (Responsible for everything to do with products that the Organisation sells)
-
Recommendation (Responsible for providing product recommendations to customers based on their past purchases)
-
Customer (Responsible for customer account details and their purchase history)
As mentioned above, each of these are capabilities in their own right that can be stitched together to support an overall User Journey.
Introducing Bounded Contexts to the Monolith
Having identified these different Bounded Contexts, the next step is to introduce them into our monolithic codebase. We should do this in an incremental way to allow us to make small changes that we can reflect on before progressing. At the end of this stage, each of the above Bounded Contexts will have a corresponding package in our codebase. Not only that, but our code components within our codebase should be organised so they live within these packages, depending on which Bounded Context they relate to, similar to what is shown below:
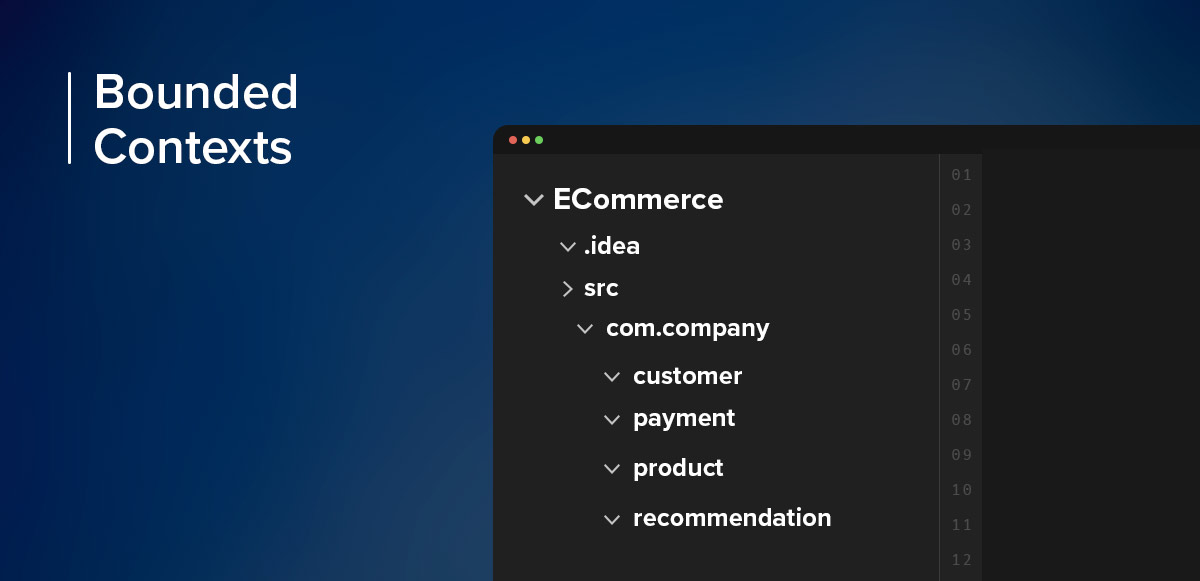
As part of this, you will likely encounter components that you think will span across multiple Bounded Contexts. For example, perhaps you have a database access component that knows how to store and retrieve all data from the database. You may be inclined at this point to introduce a “common” package but actually, that is not really what we want to do. Why? Well, each Bounded Context in your current monolith should be able to stand alone by itself. We want to design for them to be autonomous as much as possible (ultimately this will allow us to extract them out into separate codebases and deployable artefacts at a later stage should we want to). So, the better thing to do is to decompose the common database access component and introduce new ones for each individual Bounded Context. For example, we might introduce a PersonRepository and a ProductRepository for various database access across those Bounded Contexts. At that point we can also take a step forward and introduce database access components for each individual domain entity we have within each Bounded Context, to reduce coupling even more.
Maintaining Modularity in the Monolith
Having done the hard work of identifying various Bounded Contexts and re-structuring our monolith codebase around them as packages, we should now have ourselves a Modular Monolith. But, we want to make sure that it does not regress back to an unstructured codebase or we don’t introduce undesired dependencies between packages. There are various tools that can support us with this. For example, in the Java world there is a testing framework called ArchUnit that allows Unit Tests to be written that enforce the structure of your codebase. For example, going back to our e-commerce system example we could write a Unit Test that ensures that all of our recommendation-related components live within the recommendation package. Should we break that rule then this Unit Test will fail and we will have quick feedback that we’ve violated the modularity of our codebase.
From Monolith To MicroServices
Having identified the various seams (or Bounded Contexts), introduced them to our codebase and then rearranged the code to fit nicely into them, we now have our “Modular Monolith”. At this point, you might start thinking about moving towards a MicroServices architecture. Before doing so, I would recommend giving some time for your new codebase structure to “bed-in”. You want to be confident that the Bounded Contexts you have introduced and organised your codebase around are appropriate. One way of doing this is to review your team’s backlog and the Organisation’s feature roadmap. Are there any upcoming features that would challenge your current Bounded Context modelling? If so, you should hold off extracting MicroServices and spend some more time on those Bounded Contexts and codebase structuring.
But why is this so important? The reason is these Bounded Contexts are going to be how you migrate away from monolith to MicroService. As stated previously, each Bounded Context in your now Modular Monolith should be able to stand alone by itself as a separate service. Re-organising across services is expensive and challenging. It’s far easier to reorganise when everything is still in the same codebase.
Not only is it important to have the correct modelling of the Bounded Contexts in your monolith before considering extracting MicroServices, but it’s also vital that your team is applying good technical practices around it. Your team should already be embracing a culture of automation. The process of deploying the monolith to production should be fully automated. This includes testing, packaging, versioning, deployment. All of these are key foundational practices that need to be in place for a MicroService architecture to be successful. Along with those, there are the observability aspects too - log aggregation, monitoring, alerting for example. Without these practices in place, supporting a MicroServices architecture is very difficult.
Understanding the Justification for MicroServices
Once we have the foundations in place of technical practices and a “Modular Monolith”, we are free to start thinking about splitting the monolith codebase to extract out MicroServices. However, it’s important to understand the reasons why you would want to move to MicroServices. A well-structured monolithic architecture may well be good enough for your use-case. There are a number of benefits of a MicroServices architecture but it’s important to assess whether these benefits would solve a problem you currently have. There is no value in adopting MicroServices just for the sake of doing so. Some of the aforementioned benefits are:
Having MicroServices, gives us the freedom to make technology choices on a per-service basis rather than a one-size-fits-all approach. This allows us to pick the right tool for each job. For example, for a MicroService that is responsible for data processing, a language such as Python might be a good fit due it’s flexibility and large array of data processing and mathematical packages and libaraies.
MicroServices offer the ability to isolate failure to allow the wider system to continue functioning and degrade gracefully. For example, going back to our e-commerce example from earlier in the article if the Recommendation MicroService failed, it should still be possible to allow customer to use the online website and purchase goods, just without any recommendations being shown to them. In the case of failure in a monolithic system, everything would stop working. It’s important to note though that MicroServices as with all distributed systems introduce new failure modes that need to be handled too.
With a monolithic architecture, everything has to be scaled together. With independent services, we have the ability to scale just those services that require scaling. This allows us to run other services either on less powerful infrastructure or simply in fewer numbers (less running instances). When using Cloud infrastructure services, it’s also possible to configure on-demand auto-scaling strategies per service in response to peaks in traffic. This allows a much tighter control on running costs.
MicroServices introduces independently deployable units. With a monolithic architecture, each deployment is a deployment of the entire application. Having independently deployable services, means that each of these services are free to have their own release cadence. Which can also lead to a reduction in risk as the scope of deployments is now much smaller.
Extracting out MicroServices
It’s important to note that extracting out services should be done incrementally, one at a time. This gives us the time and space to learn and adapt if necessary. It also, of course, lowers the degree of risk involved. To decide which Bounded Context should be extracted into a MicroService first, we should consider a number of different factors, such as:
If there happens to be a large amount of change coming up soon in a particular area, then splitting that out into a separate component could make those changes easier. It now becomes a separate autonomous component.
Different components will be responsible for different pieces of data and this data is likely to have differing security requirements. For example, payments data is likely going to need a much higher level of security than say a recommendations component. By having them as separate components we can address the differing security concerns separately rather than having to apply a ‘one size fits all’ approach.
Extracting out separating components that define clear APIs, means we are free to make technology choices that make sense for each component in turn. For example, we may feel that a functional programming paradigm fits better for one component but another we want to adopt an Object-Oriented approach.
I have worked on many software delivery teams that have spanned multiple locations (and even time-zones). This can be difficult when everyone is working on the same codebase. By having multiple, independent components. It is possible for the team in one location to take ownership of one component and the other team take ownership of the other. This hugely reduces the co-ordination overhead between the two teams and brings a greater level of autonomy and feeling of ownership.
Summary
This article has attempted to give an overview of some of the steps you can take in order to address an unstructured, unwieldy monolithic codebase. It’s important that the Organisational Bounded Contexts in which the codebase exists are reflected and modelled as first class citizens within the codebase.
Here are the key takeaways:
-
Resist the urge to jump straight from an unstructured monolith to MicroServices architecture
-
Instead, work towards having a Modular Monolith architecture first.
-
Identify the relevant Bounded Contexts
-
Review the Bounded Contexts with the wider Organisation
-
Introduce these Bounded Contexts into your monolith codebase, gradually, by leveraging programming language mechanisms such as packages and namespaces
-
Ensure foundational technical practices are in place - embrace automation for testing, deployment, observability etc
-
Each Bounded Context within the Modular Monolith should be able to be extracted into independently deployable services.
-
When extracting services, consider rate of change, security, technology choice and team structure


/ebook%20modernizaci%C3%B3n%20+%20IA_guia%20CTOs/IA_modernisacion_form_bg.png?width=528&height=528&name=IA_modernisacion_form_bg.png)
